端到端大数据分析,全面管理数据生命周期
1. 环境配置
注:环境配置步骤建议由智领云销售人员配合完成,如系统已配好环境,用户则可跳过环境配置的操作
1.1 文档使用说明
本文档中所包含的初始化步骤需要在使用 “大数据分析” 教程之前,安排以下两类人员中的任何一种来完成
- 系统管理员 (Admin用户)
- 演示组中拥有高级权限的成员
需要运维人员检查数据流水线所需要的程序和这几个组件之间的地址是否匹配,特别是MySQL:
MySQLHiveHDFSRedis
1.2 创建独立安全组和角色
本系统安全组是同时对资源和权限进行管理的虚拟分组,权限通过角色来进行封装。每一个安全组有自己独立的角色体系,同时也可以使用公共角色(公共角色是所有安全组都有可能使用到的角色,比如每个组都有可能用到default_user这个只要普通用户权限的角色)。独立的安全组内设置的角色权限,用户勾选的选项,将直接决定当前用户进入本系统后所能看到的界面。
Step1-创建独立安全组
**(注:本手册场景以用户组demo为例,用户可根据实际情况进行调整,如无权限创建安全组,请使用系统默认安全组:Admin)** |
- 创建一个独立的安全组,比如
demo,【安全管理-安全组管理-添加安全组】点击进入,创建安全组
Step2-在安全组内创建独立角色(也可不创建,使用默认角色)
- 在角色管理界面,点击安全组下拉框,选择需要的安全组进入
- 在
demo安全组下面添加角色,比如试用者
Step3-配置独立角色的权限(也可不配置,使用默认权限)
- 配置
试用者这个角色的相关权限,参考以下推荐配置
| 类目 | 内容 | 备注 |
|---|---|---|
| 目录权限管理 | ||
| — | 快速体验 | 勾选 |
| — | 监控面板 | 不勾选 |
| — | 应用管理 | 勾选 |
| — | 安全管理 | 不勾选 |
| — | 记录 | 仅保留操作记录 |
| — | 附加工具 | |
| 接口权限管理 | — | 保持默认 |
| 视角设置 | — | |
| — | 内部入口页 | 快速体验 |
| — | 外部入口跳转方式 | 跳转到内部入口页面 |
| — | 快速入口 | |
| — | — | 在Hue里面运行Hive程序 |
| — | — | 课程市场 |
| — | — | 在Zeppelin里面浏览并运行Spark程序 |
| — | — | BDOS Data Service |
| — | — | FlowMan |
| — | — | Superset |
| — | 快速入口排序 | 无特殊要求 |
以添加应用“在Hue里面运行Hive程序”为例,参考截图
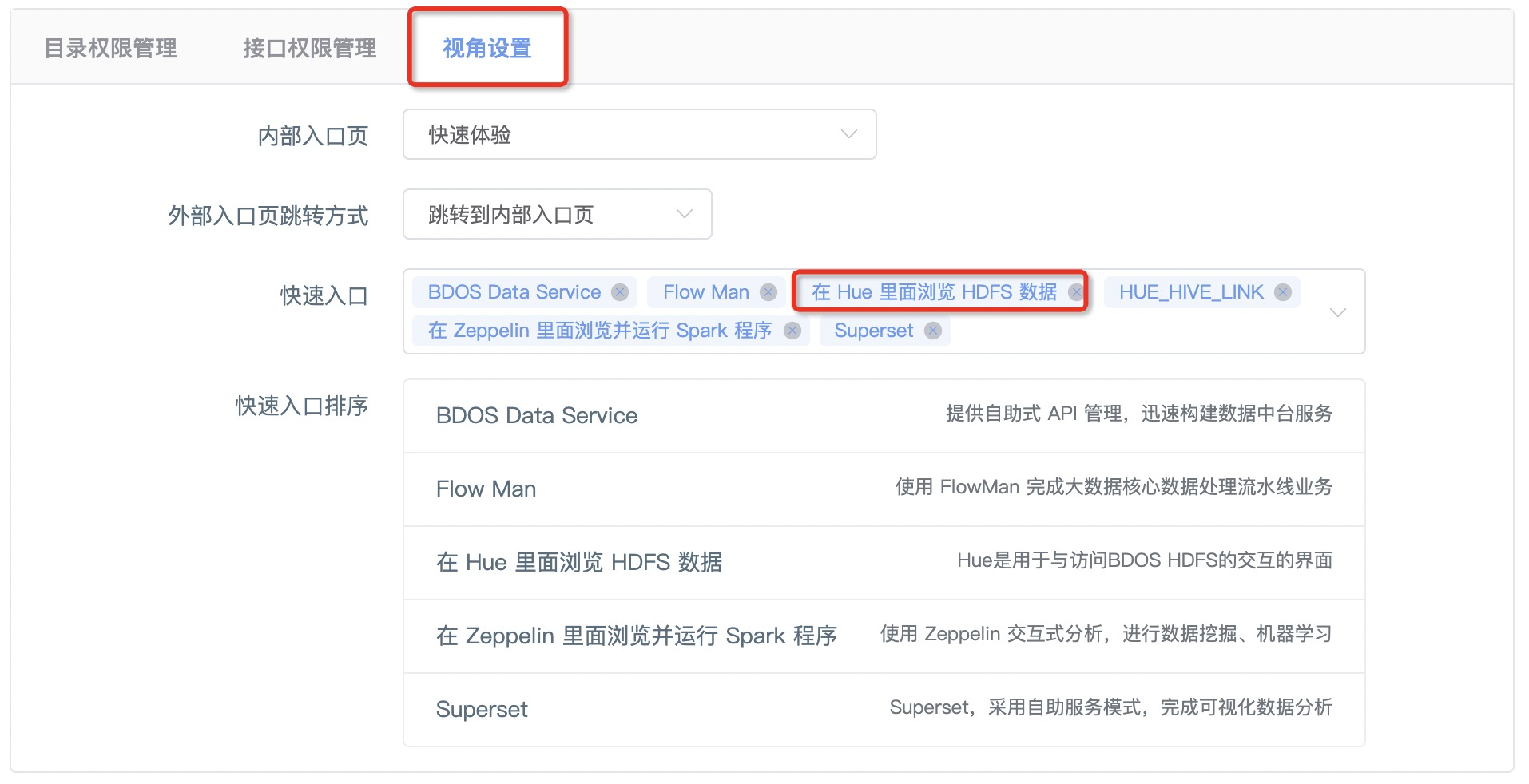
注:此处可根据需要自行添加
Step4-用户管理
创建新的账号
在用户管理界面点击添加用户,输入用户的邮箱地址和用户名,英文用户名请用小写字母。本教程以添加用户demouser01为例
添加用户到对应的安全组。在安全管理界面点击安全组管理,选择目标安全组进入,点击下拉框选择用户后进行添加(同一用户可以被添加至不同的安全组,并在不同安全组下配置不同的角色),为添加的用户设置对应的角色
2. 准备环境
注:准备环境章节的内容,建议在智领云销售人员的配合下完成,如系统已完成环境准备,用户则可跳过环境准备章节的操作
2.1 容器环境
容器环境指基于大数据的容器准备,本教程需要连接Hive的Beeline环境,系统已默认准备Hive的容器环境,可直接供用户调用。
本系统的Worker列表即为容器列表,容器为不同类型的数据处理准备了相应的环境。例如Hive的Beeline环境:basic-etl-worker、Spark的脚本环境:Spark等。
用户通过【程序坞 - Worker列表】进入。

2.2 配置数据源
配置数据源以供爬虫爬取的数据临时存储。
Step1-登录FlowMan
使用 admin/demo组账号登录 BDOS,在快速登录点击 FlowMan参考截图,进入FlowMan界面后,通过【资源集成中心-添加数据库】进入。
Step2-添加数据库集成MySQL数据源
点击「资源集成中心-添加数据库」,并参考表格进行填写
| 名称 | spider_demo | 教程中使用的名字 |
|---|---|---|
| 数据库类型 | MySQL | 保持默认 |
| 环境 | 仅勾选production |
教程场景仅仅涉及一个环境 |
| 数据库名称 | demo | 场景提供的数据库 |
| 主机 | admin-linktime-mysql.marathon.mesos | 教程提供的数据库地址 |
| 端口 | 3306 | 教程提供的数据库地址,实际中需要和管理员确认 |
| 用户名 | root | 教程提供的默认数据库用户名,实际中需要和管理员确认 |
| 密码 | xxx | 请和系统管理员或智领云销售人员进行确认 |
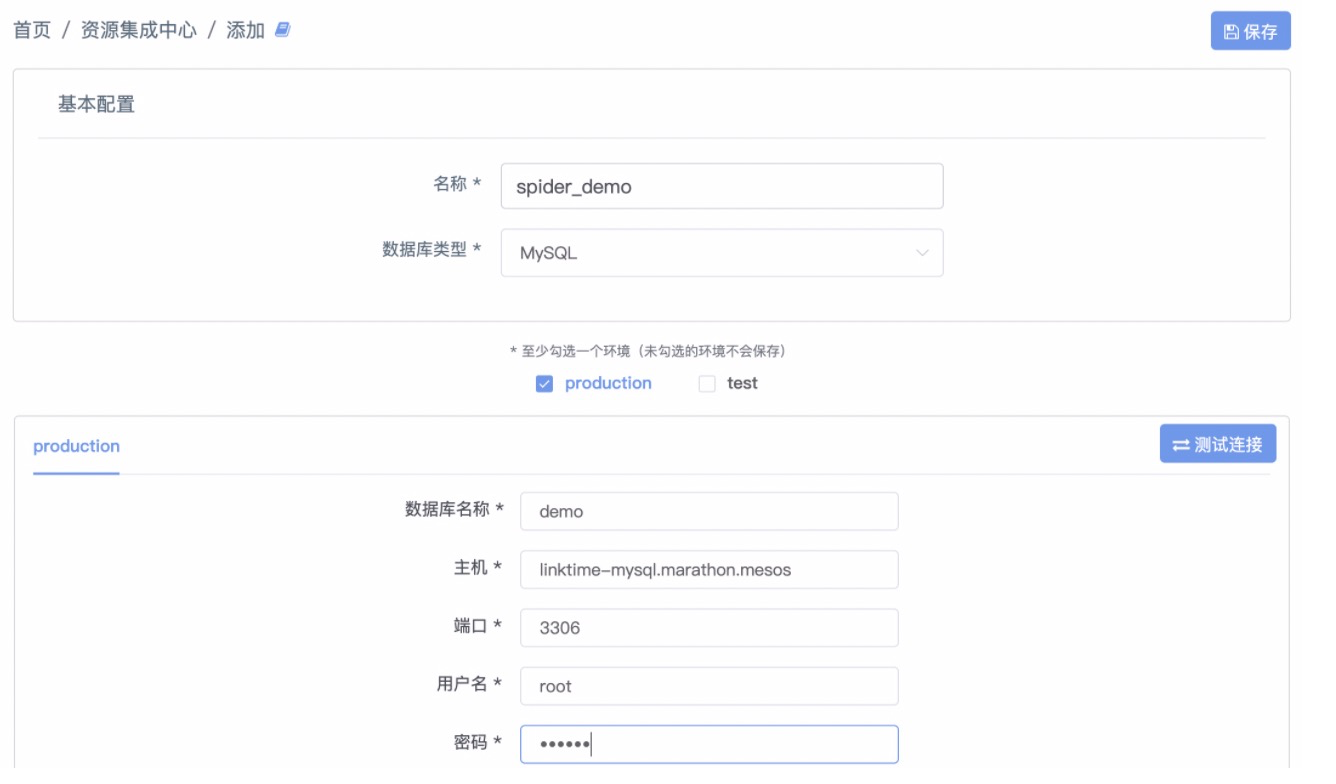
Step3-保存集成
填写完毕后,点击「测试连接」在得到测试通过的提示后,点击保存
2.3. 添加程序
程序是跑在容器里面执行特定任务的一段代码,可以是一段Python脚本,也可以是一条SQL语句。
Step1-下载程序
- 阅读下表两个程序的作用,通过下载链接,保存至本地并等待之后步骤使用
| 序号 | 内容 | 备注 | 下载 | 链接 |
|---|---|---|---|---|
| 01 | user-refresh-table.tgz | 初始化数据处理结果存放数据表程序 | 点击下载 | http://linktime-public.oss-cn-qingdao.aliyuncs.com/bdos-tutorial-2/setup/user-refresh-table.tgz |
| 02 | user-spider-demo.tgz | 爬虫程序 | 点击下载 | http://linktime-public.oss-cn-qingdao.aliyuncs.com/bdos-tutorial-2/setup/user-spider-demo.tgz |
| 03 | hive-schedule.tgz | Hive客户端程序,系统已预置 | - | - |
注:hive-schedule-1.0.tgz程序,本系统已经预制,无须用户单独添加
Step2-登录FlowMan & 添加程序
使用 admin/demo组 账号登录 BDOS,在快速登录点击 FlowMan,参考截图,进入程序坞-新增程序
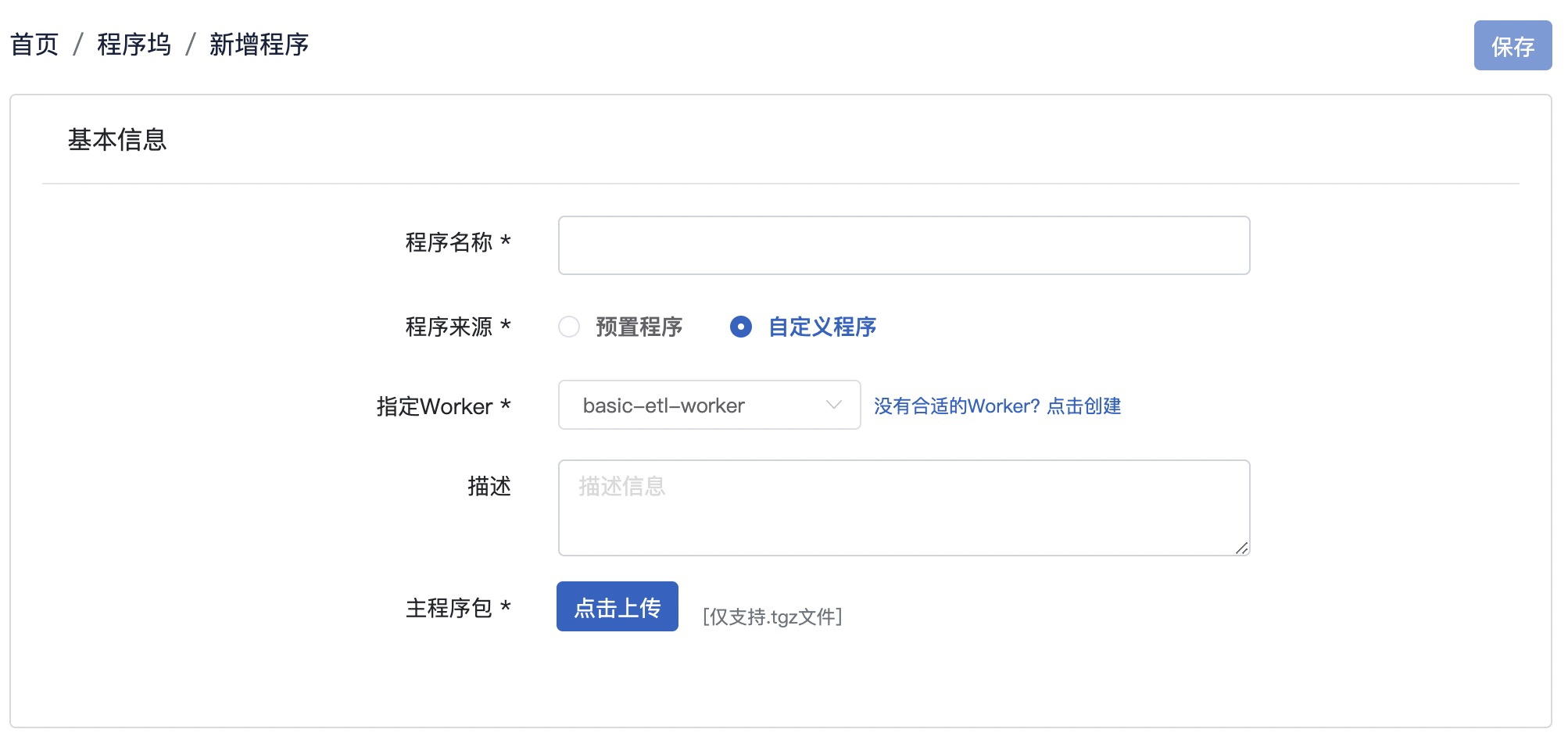
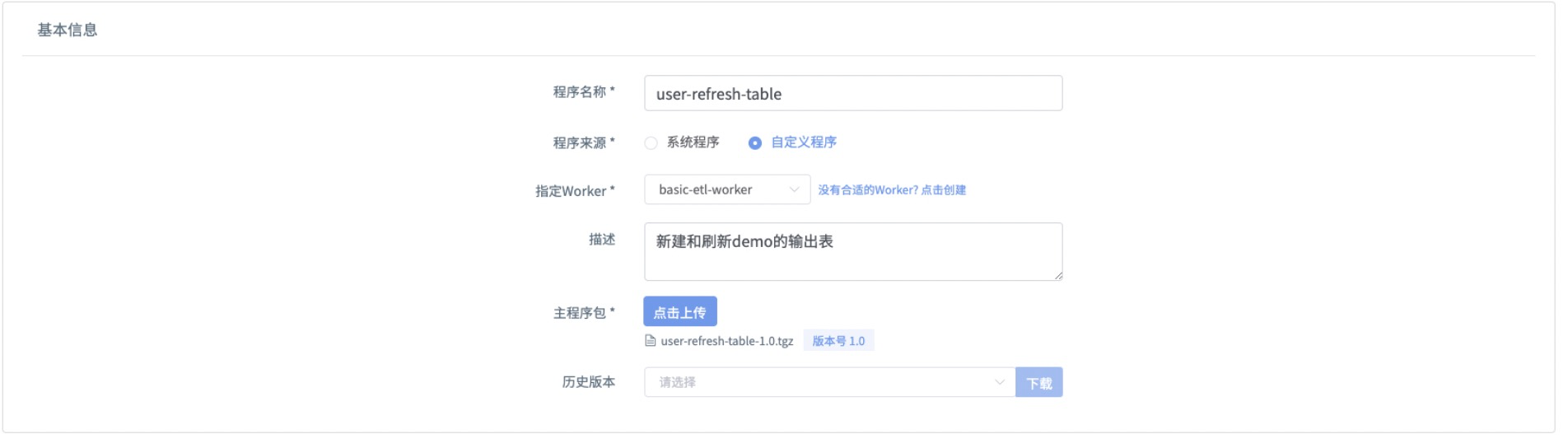
Step3-添加 user-refresh-table
本脚本由Python编写,主要作用是初始化爬虫目标数据库程序,供本案例使用。
- 如图所示,参考下表填写
| 条目 | 内容 | 备注 |
|---|---|---|
| 程序名称 | user-refresh-table | |
| 程序来源 | 自定义程序 | 系统设置预置程序和自定义程序两种类型,用户添加的程序均选择自定义程序 |
| 指定worker | basic-etl-worker | 下拉框选择,为程序指定运行的容器环境 |
| 描述 | 新建和刷新demo的输出表 | |
| 主程序包 | 点击上传 | 选择user-refresh-table.tgz上传 |
注:用户也可通过其他途径预初始化数据库,如在Hue进行操作。
Step4-添加 user-spider-demo
此脚本是由Python编写的爬虫程序,代码中已经事先写好存入的目标数据库,即为上文所配的MySQL数据源,供本教程使用。
- 参考截图,进入
程序坞-新增程序,参考表格进行填写 - 点击
保存按钮
| 条目 | 内容 | 备注 |
|---|---|---|
| 程序名称 | user-spider-demo | |
| 指定worker | basic-etl-worker | 下拉框选择,为程序指定运行的容器环境 |
| 描述 | 爬虫程序 | |
| 主程序包 | 点击上传 | 选择user-spider-demo.tgz上传 |

添加完成后,点击保存
Step5-添加 hive-schedule
此脚本由Python编写,通过H2JDBC连接Hive,同时接受SQL语句。脚本中已经编写好JDBC的相应配置,如:Hive地址、端口、数据库名称等信息。本系统已默认为用户添加,用户无须单独添加
2.4 开通HDFS权限
本教程以demo安全组用户demouser01添加HDFS权限为例,为用户组添加HDFS权限后,用户组可以对本目录进行读写。
注:如系统已为demouser01添加HDFS权限,请忽略此步骤
Step1-登录FlowMan
- 使用 admin 账号登录 BDOS,在
快速登录点击 FlowMan - 参考截图,进入
安全管理-授权管理 添加Hadoop策略
Step2-填写策略基本配置
- 如图所示,参考下面表格填写
| 条目 | 内容 | 备注 |
|---|---|---|
| 策略名称 | grant_hdfs_to_demo | 可替换 |
| 策略描述 | 开通对 HDFS 的权限给 demo group | 可替换 |
| path | / | 点击添加按钮(根目录代表所有) |

Step3-填写策略白名单
- 点击
添加,如图所示,参考下面表格填写
| 条目 | 内容 | 备注 |
|---|---|---|
| 组 | demo | 在教程的场景中不能更改 |
| 用户 | 保持为空 | |
| 权限 | 全部 | 勾选全部 |

Step4-保存策略
- 点击
保存
2.5 开通Hive权限
本教程以为demo安全组用户demouser01添加Hive权限为例,为用户组添加Hive权限后,用户组可以对上文创建的Hive库进行相应的权限操作。
注:如系统已为用户demouser01添加Hive权限,请忽略此步骤
Step1-登录FlowMan
- 使用 admin 账号登录 BDOS,在
快速登录点击 FlowMan - 参考截图,进入
安全管理-授权管理
Step2-新增 Hive 策略
- 如图所示,点击下拉框,选择
Hive策略
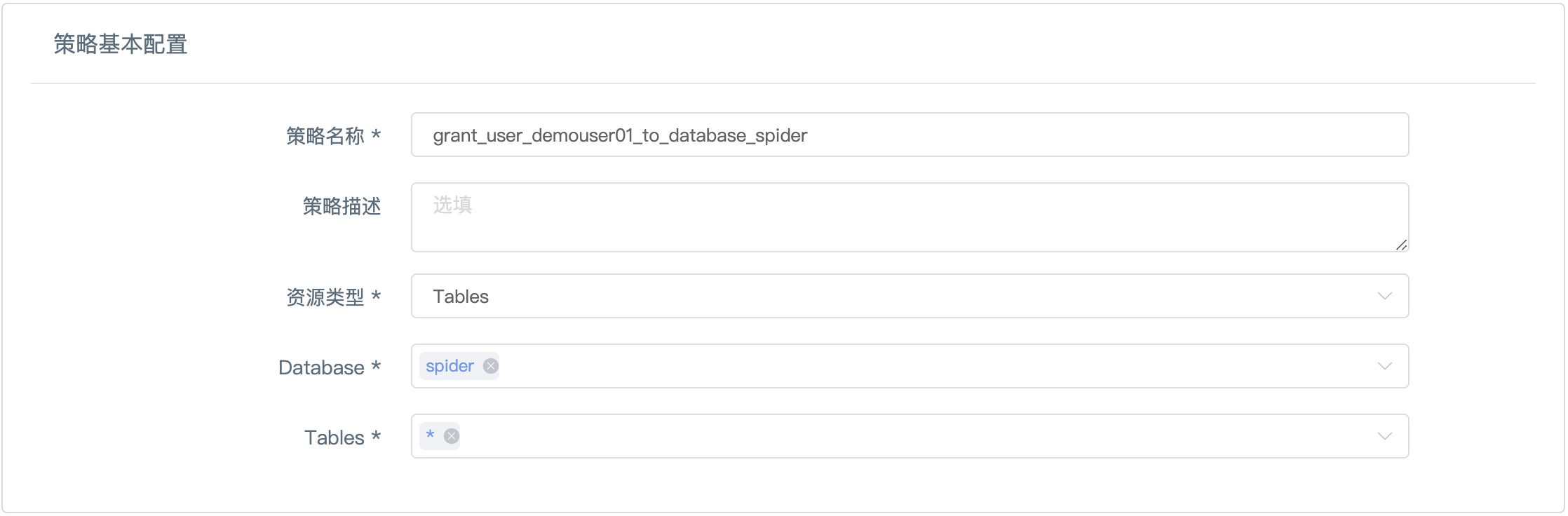
Step3-填写策略基本配置
- 点击系统默认创建的Hive策略:grant_user_demouser01_to_database_spider进入
- 如图所示,参考下表更改填写
| 条目 | 内容 | 备注 |
|---|---|---|
| 策略名称 | grant_user_demouser01_to_database_spider | 可替换 |
| 策略描述 | 开通对 Hive 的权限给 demo group | 可替换 |
| 策略类型 | Tables | 保持默认 |
| Database | spider | 手工输入spider |
| Table | * | 下拉框选择,*代表对当前数据库下所有的表都有操作权限 |
Step4-策略白名单
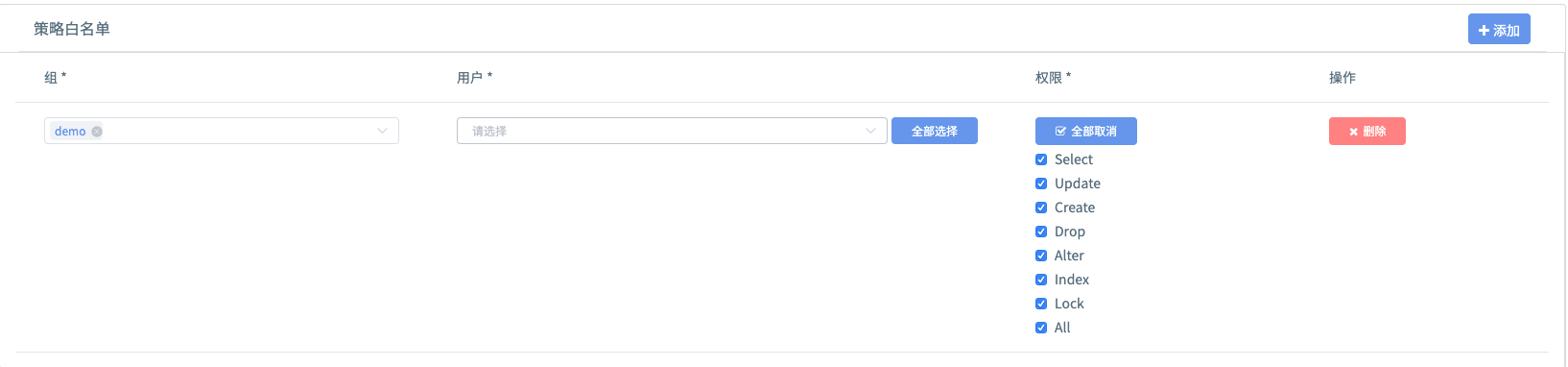
- 点击
添加,如图所示,参考下面表格填写
| 条目 | 内容 | 备注 |
|---|---|---|
| 组 | demo | 在教程的场景中不能更改 |
| 用户 | 保持为空 | |
| 权限 | 全部 | 勾选全部 |
Step5-保存策略
- 点击
保存
2.6 程序运行并初始化数据库
2.6.1 试运行Hive JDBC程序并初始化Hive数据库(hive-schedule)
Step1-登录FlowMan
- 使用 Admin 账号登录 BDOS,在
快速登录点击 FlowMan - 参考截图,进入
程序坞-程序列表
Step2-初始化Hive数据库
有两种方式对Hive数据库进行初始化,方式一:通过Hue输入SQL语句,初始化Hive数据库;方式二:通过现有hive-schedule脚本输入建表SQL语句。本教材采用方式二,步骤如下图所示
- 选择内置的 Hive 程序:hive-schedule
点击进入hive-schedule程序,保持默认选项,点击运行
create DATABASE if NOT EXISTS spider |
试运行结果成功输出后,点击运行
2.6.2 初始化数据处理结果存放数据表(user-refresh-table)
经过采集、Hive加工后,最终结果存放到MySQL表供业务部门展示之用。
本系统程序已经预制SQL建表语句,所以执行时无须添加任何参数。运行完后可通过Hue查看目标数据库是否建表成功。
- 程序列表界面选择自定义程序:user-refresh-table,点击进入
- 自定义程序参数:“MYSQL_HOST”:“admin-linktime-mysql.marathon.mesos”
保持默认选项,选择版本号后点击试运行
查看运行结果
2.6.3 试运行爬虫程序(user-spider-demo)
- 程序列表界面选择自定义程序:user-spider-demo,点击进入
- 自定义程序参数:“MYSQL_HOST”:“admin-linktime-mysql.marathon.mesos”
保持默认选项,选择版本号后点击试运行
查看运行结果
2.7. 创建FlowMan工作流所需的表
2.7.1 创建MySQL表
从BDOS平台的快速体验菜单选择进BDOS Hue界面图标点击进入,创建数据采集调度作业所需的MySQL输入表:demouser01_newsRank1Hour
本系统作业每小时整点采集一次,所采集的数据会存入以上所建的表
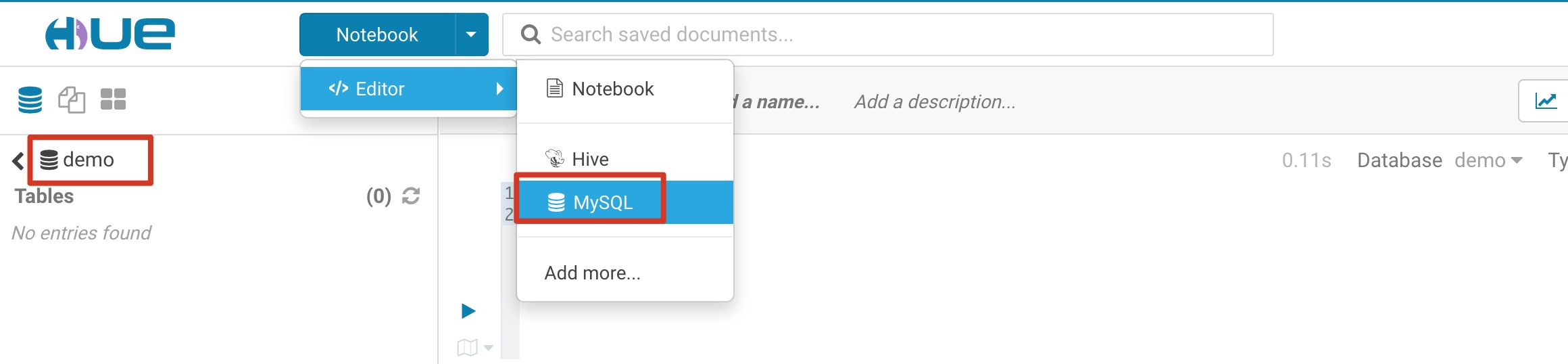
Step1: 切换Hue页面编辑器到MySQL
点击Notebook->Editor->MySQL,参考截图:
Step2: 在编写主程序区域填写 SQL语句
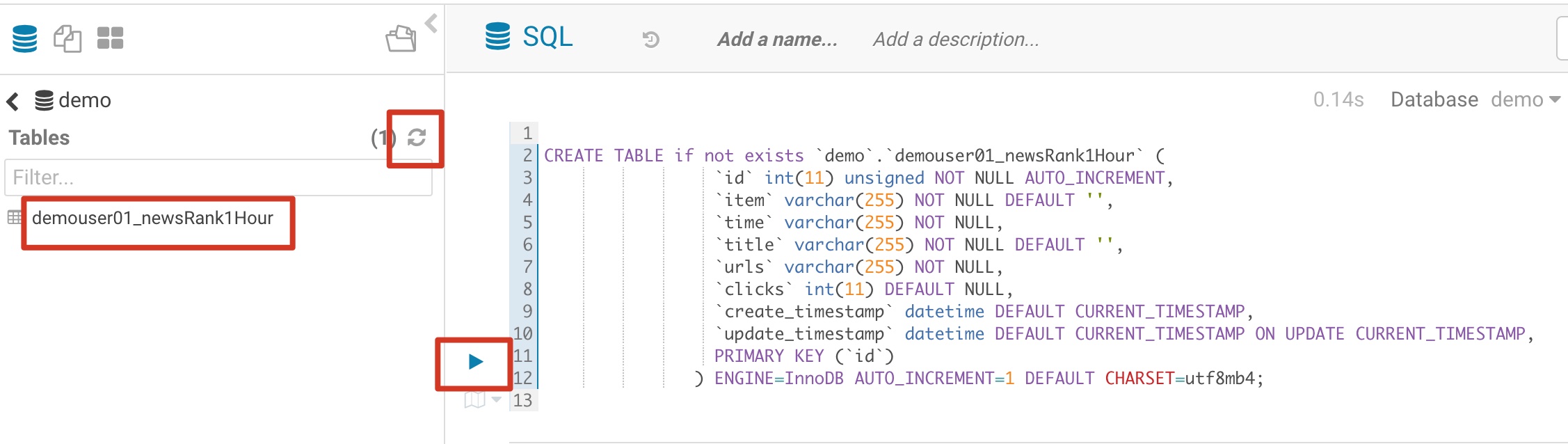
创建数据采集调度作业所需的MySQL输入表demouser01_newsRank1Hour,参考如下SQL语句和截图
CREATE TABLE if not exists `demo`.`demouser01_newsRank1Hour` ( |
参考截图,点击运行后刷新
2.7.2 创建Hive表
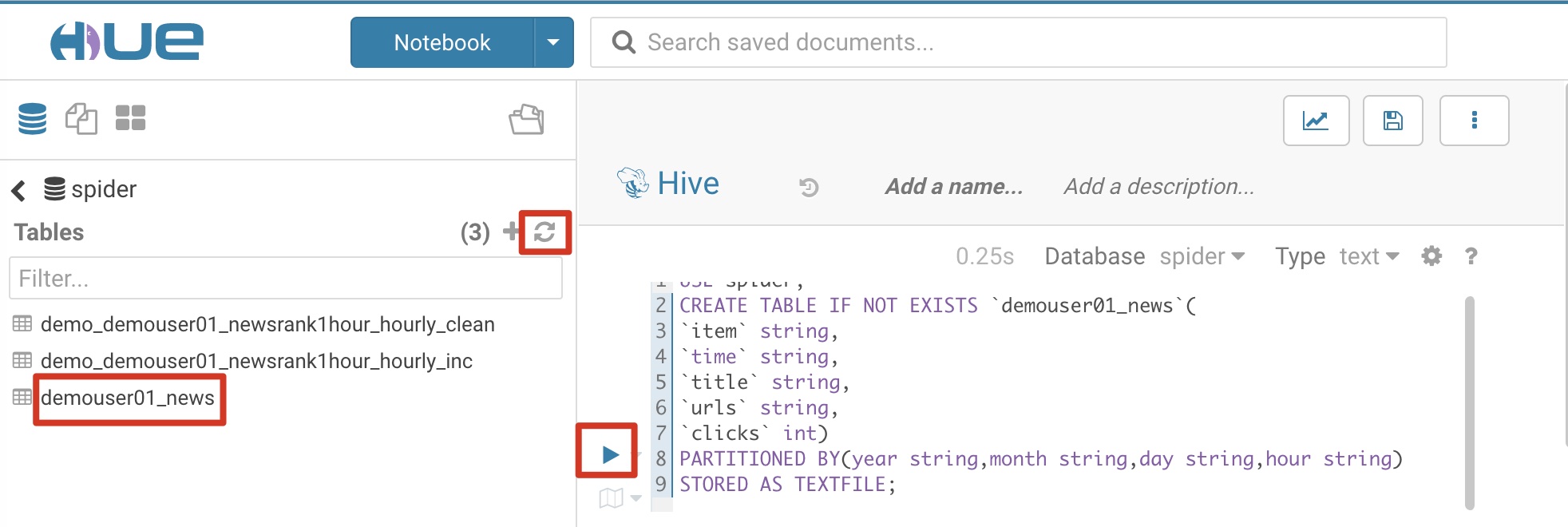
进入Hive界面,创建以下几张表:
- 创建从数据采集调度作业所需的MySQL表demouser01_newsRank1Hour通过Sqoop抽取到Hive的贴源表demo_demouser01_newsRank1Hour_hourly_inc
- 创建Hive数据清洗后所存放数据的目标表demo_demouser01_newsRank1Hour_hourly_clean
- 创建数据统计加工后的目标表demouser01_news
Step1: 切换Hue页面编辑器到Hive
用户从BDOS平台点击快速体验,点击BDOS Hue图标进入,参考截图:
进入BDOS Hue之后,点击Notebook->Editor->Hive,参考截图:
Step2: 在编写主程序区域填写 SQL语句
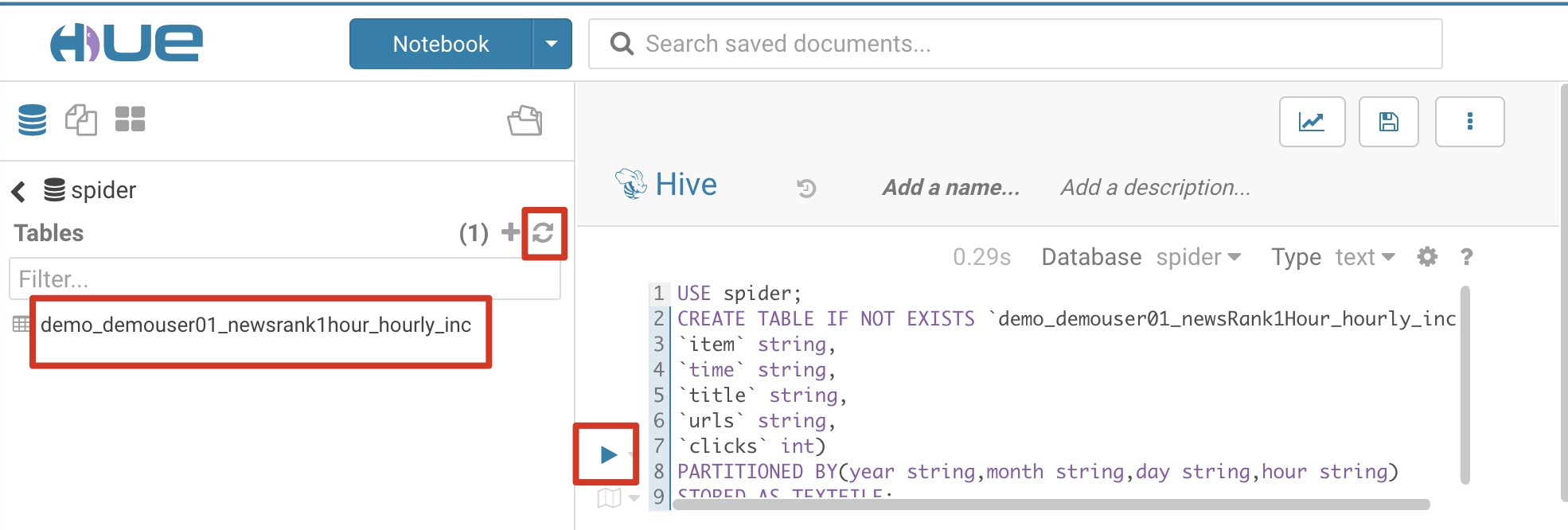
创建从数据采集调度作业所需的MySQL表demouser01_newsRank1Hour通过Sqoop抽取到Hive的贴源表demo_demouser01_newsRank1Hour_hourly_inc,作为Sqoop作业的输出表和数据清洗作业的输入表,参考SQL语句和截图:
USE spider; |
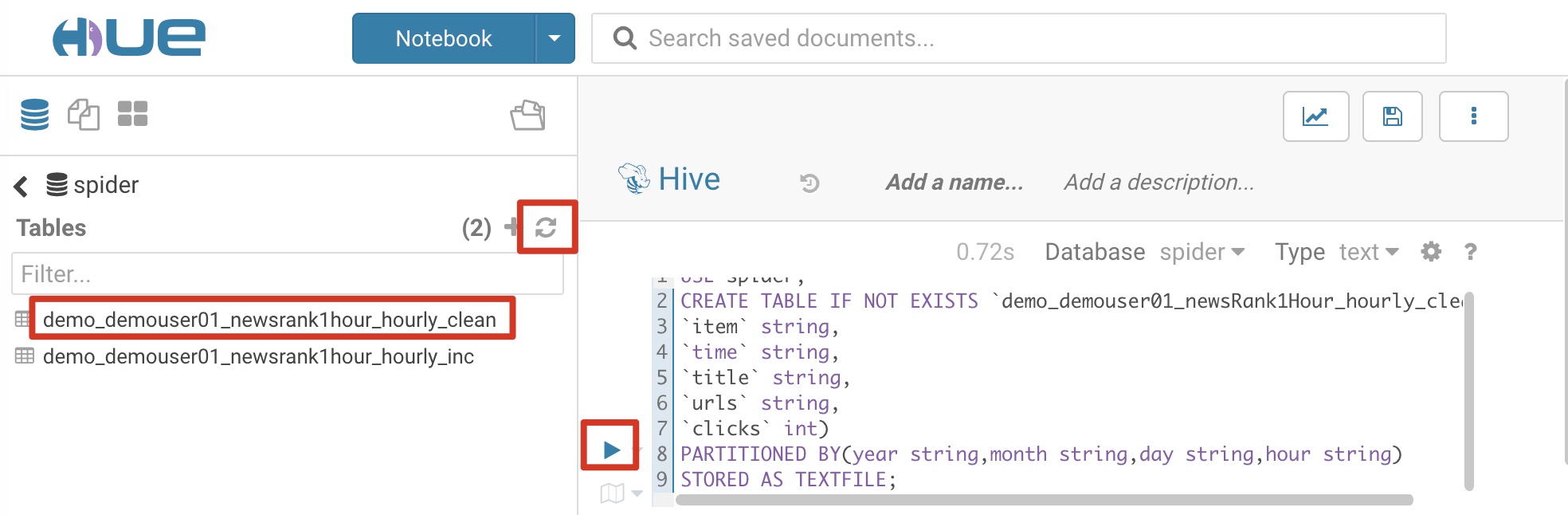
创建Hive数据清洗后所存放数据的目标表:demo_demouser01_newsRank1Hour_hourly_clean,作为数据清洗作业的输出表和数据统计作业的输入表,参考SQL语句和截图
参考截图,点击运行后刷新
USE spider; |
参考截图,点击运行后刷新
创建数据统计加工后的目标表:demouser01_news,作为数据统计作业的输出表和,参考SQL语句和截图
USE spider; |
参考截图,点击运行后刷新
3.实验准备
3.1 实验目的
数据开发的目的是使用各种工具来分析数据,从数据中产生可指导行动的商业洞见,是从数据到价值的转换过程。在很多场景下,数据分析人员需要对海量的数据进行快速的分析,性能上要像在传统的数据仓库中运行查询语句一样,在几秒钟内得到数据分析的结果。而本手册将以教程的形式,端到端的向大家展示一个典型的大数据分析实例,包括数据采集、数据处理和数据分析这三个步骤:
- 在BDOS大数据平台,用户可以发布一个爬虫程序,通过爬虫程序定期爬取网易网页新闻,并将这些新闻数据存入MySQL数据库中;
- 用户接下来可以定义一个采集作业,定期将MySQL的新闻数据采集到分布式文件系统HDFS;
- 然后用户可以在Hive中对新闻数据进行清洗并统计,再将统计后的数据定期导入到MySQL数据仓库中;
- 最后用户可以使用Superset,将MySQL数据仓库中的统计数据以可视化的方式展示出来,分析网易新闻的受欢迎程度。
3.2 实验构架图
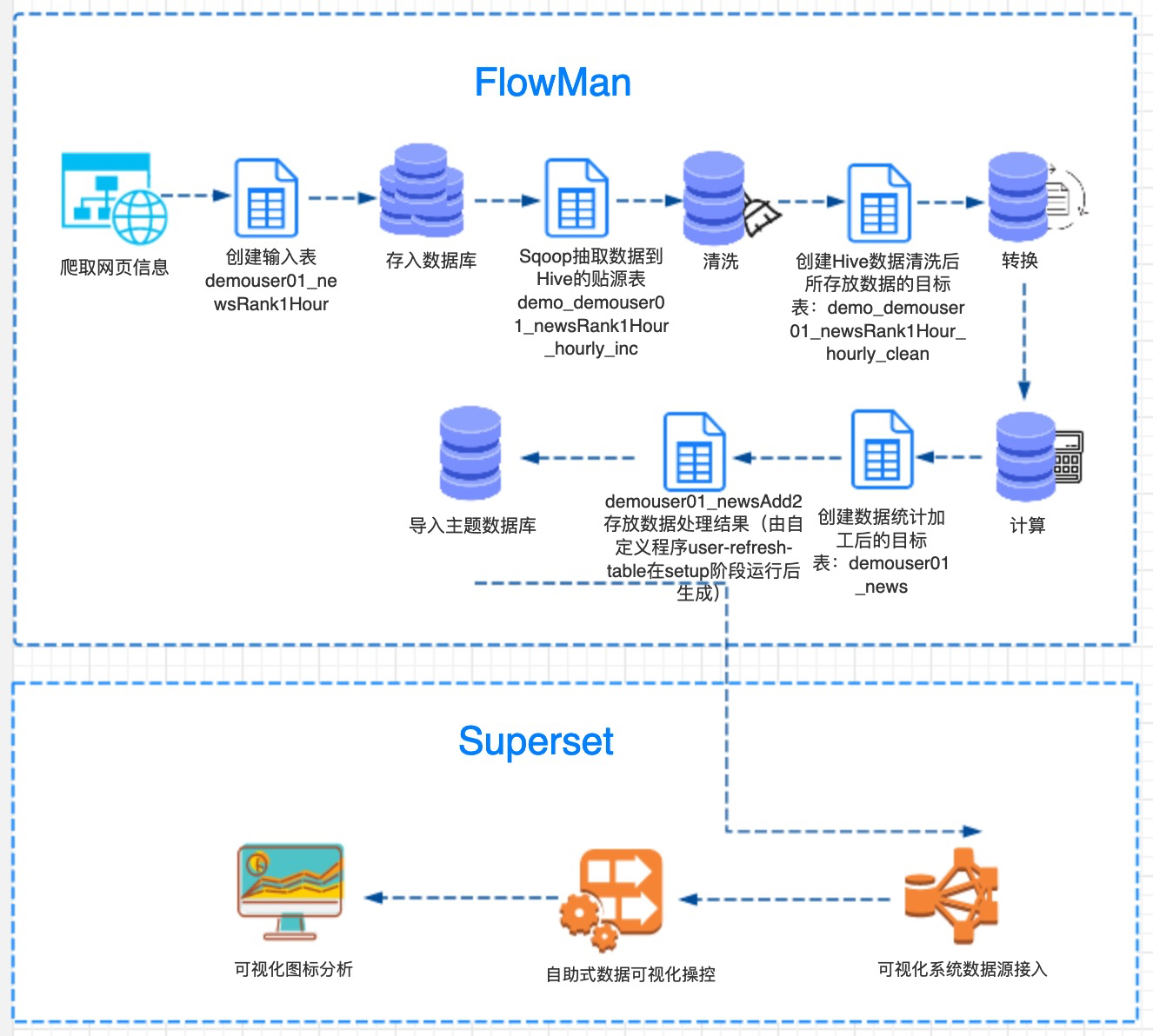
- BDOS 作为底层的大数据操作系统支撑整个端到端的整个数据生命周期
- 外部数据通过爬取、数据库、集成等等方式流入平台
- 通过在 BDOS 上发布的调度系统 FlowMan,进行一些列的数据加工
- 最后无缝衔接给在平台上发布的 Superset,进行数据分析和可视化
- 整个过程在不同的组件之间使用统一账号,统一验证
- 用户无需做额外的安装操作
查看原始数据
实验使用网易新闻排行榜作为数据源,网址
联系你的管理员
- BDOS 支持多用户,使用之前请联系你的管理员(或 BDOS售前)帮助你创建一个账号,并加入到相应的安全组,并编入对应的安全策略白名单
- 本教程使用一个演示账号: demouser01
注:本手册适用于任何需要体验武汉智领云科技有限公司大数据分析相关产品的用户。
4.步骤详解
注:请严格遵照文档操作步骤进行
用户从【作业管理-新建自定义作业】进入界面。
4.1 创建爬取调度作业
Step1: 打开作业管理
使用导航「作业管理」,完成基于一个程序创建一个调度作业的操作
Step2: 创建自定义作业
通过导航至「作业管理-新建自定义作业」,参考截图,创建自定义作业
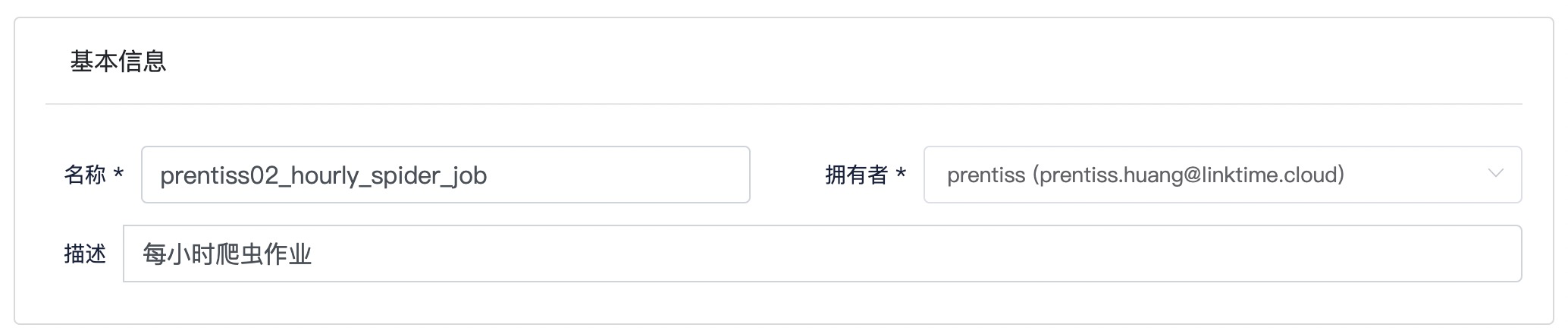
Step3: 填写基本信息
参考截图以及表格信息,填写基本信息
| 条目 | 内容 | 备注 |
|---|---|---|
| 名称 | demouser01_hourly_spider_job | demo为安全组名称,可使用实际安全组替换demo,使用用户名_替换demouser01,以免造成重名冲突 |
| 拥有者 | demouser01 | 下拉框选择自己的用户名 |
| 描述 | 每小时爬虫作业 | 可替换 |
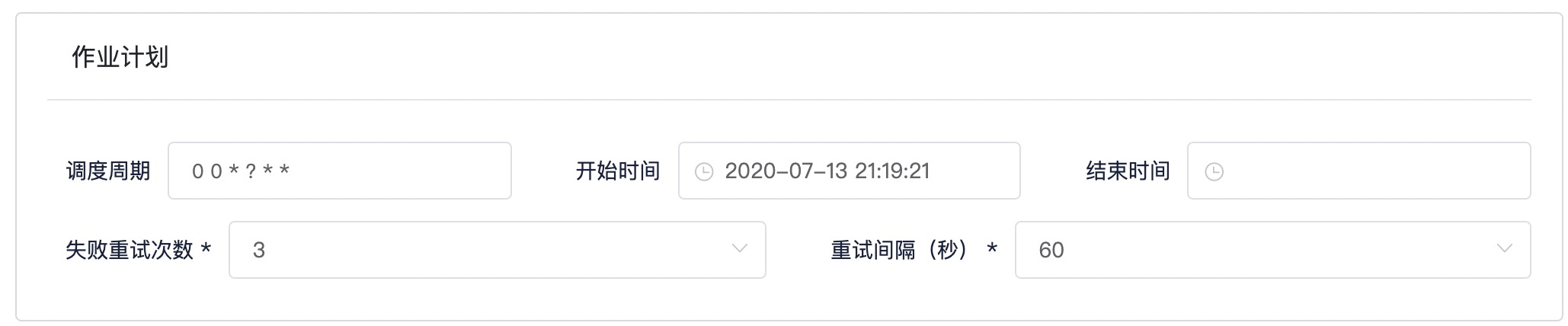
Step4: 填写作业计划
参考截图以及表格信息,填写作业计划
| 条目 | 内容 | 备注 |
|---|---|---|
| 调度周期 | 00*?** | cron表达式,使用下拉框选择对应语义: 每小时运行一次 |
| 开始时间 | 离当前时间最近的过去整点时间 | 点击输入框改动时间为离当前时间最近的过去整点时间,选择确定 |
| 结束时间 | 空置 | 保持默认 |
| 失败重试次数 | 3 | 保持默认 |
| 重试间隔 | 60 | 保持默认 |
Step5: 选择程序和版本
参考截图以及表格信息,填写自定义程序
| 条目 | 内容 | 备注 |
|---|---|---|
| 程序名称 | user-spider-demo | 从下拉框选择内置爬虫程序 |
| 版本号 | 1.0 | 从下拉框选择程序的版本号 |

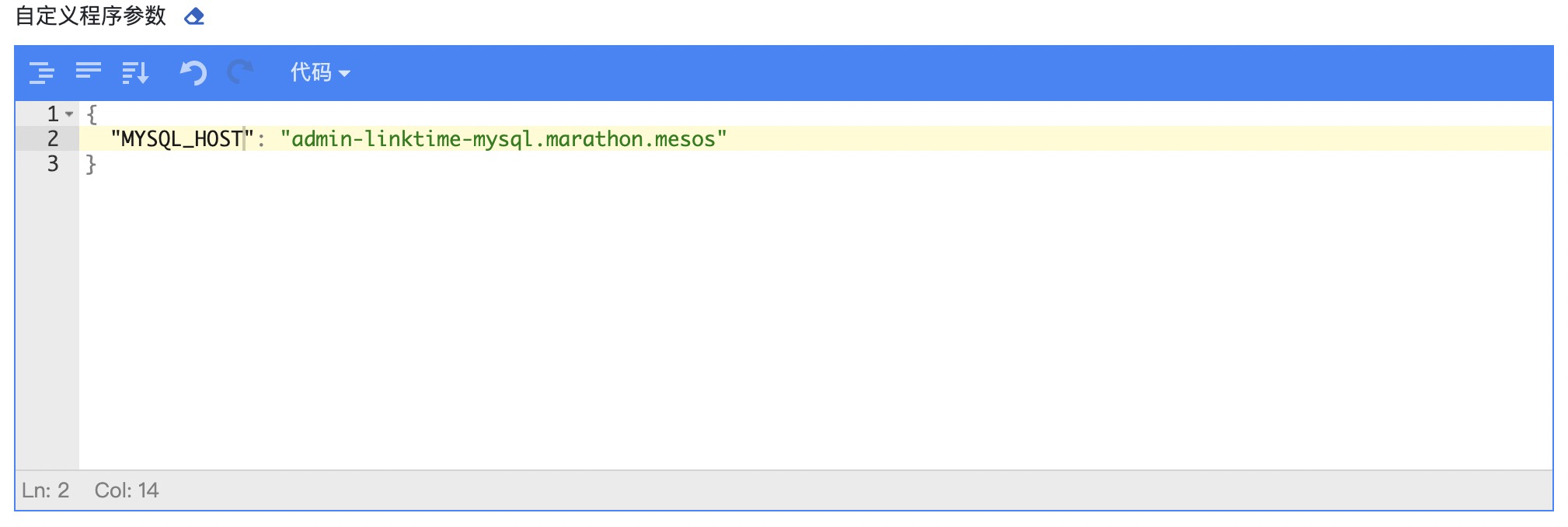
自定义程序参数
{ "MYSQL_HOST": "admin-linktime-mysql.marathon.mesos" } |
Step7: 完成创建
完成填写之后,点击右上角创建
Step8: 查看作业列表
最后,使用导航「作业管理-作业列表」可以在列表里面看见创建好的作业,此时先不正式运行作业,因为在后面会把数个作业做成一个工作流,自动化运行
注: 用户此时应该看到的是,使用
用户名_代替demouser01的作业

4.2 创建数据采集调度作业
当数据被采集到目标数据库之后,就开始对数据进行操控,首先将数据从
Mysql采集到Hive数据库
Step1: 创建Sqoop作业
通过导航来到「作业管理-新建Sqoop作业」,参考截图,创建Sqoop作业

Step2: 填写基本信息
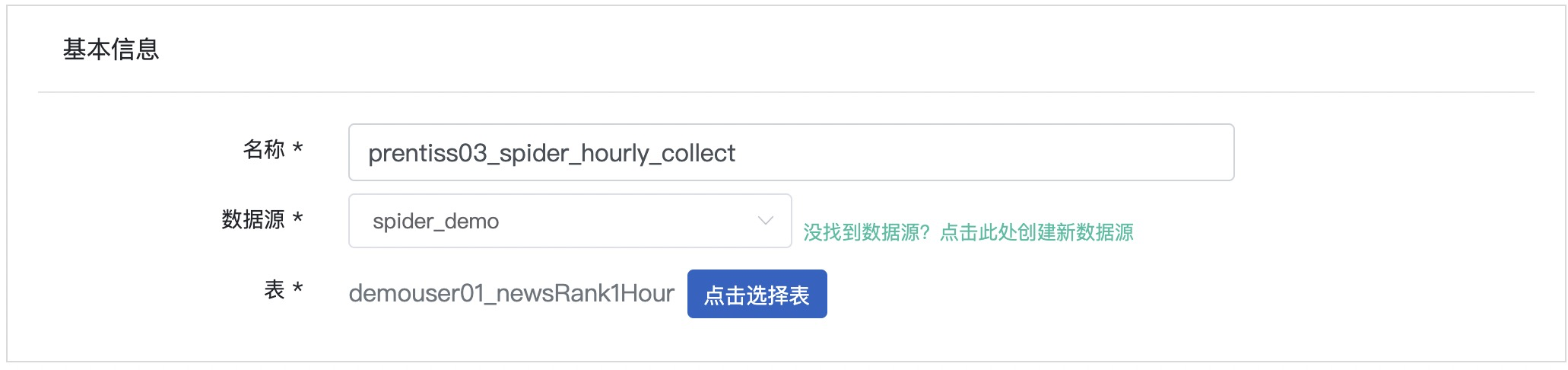
参考截图以及表格信息,填写基本信息,截图仅为示例,作业名称可替换
| 条目 | 内容 | 备注 |
|---|---|---|
| 名称 | demouser01_spider_hourly_collect | demo为安全组名称,可使用实际安全组替换demo,使用用户名_替换demouser01,以免造成重名冲突 |
| 数据源 | spider_demo | Setup阶段创建的数据源 |
| 表 | demouser01_newsRank1Hour | 使用实验提供的数据表 |
Step3: 填写采集配置
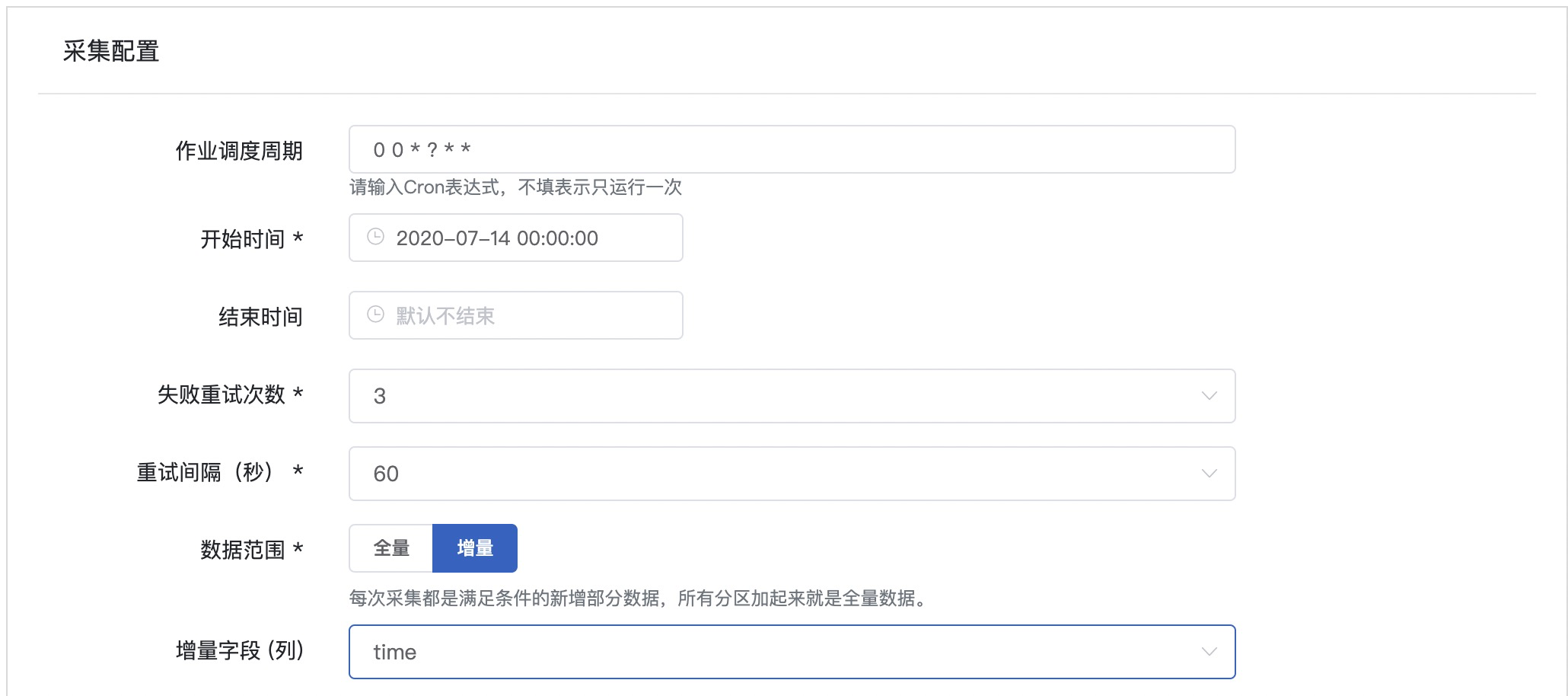
参考截图以及表格信息,填写采集配置
| 条目 | 内容 | 备注 |
|---|---|---|
| 作业调度周期 | 0 0 ? * | Cron表达式,每小时运行一次 |
| 开始时间 | 保持默认 | 保持默认 |
| 结束时间 | 置空 | 保持默认 |
| 失败重试次数 | 3 | 保持默认 |
| 重试间隔 | 60 | 保持默认 |
| 数据范围 | 增量 | 因为是周期性采集 |
| 增量字段(列) | time | 以时间维度增量 |
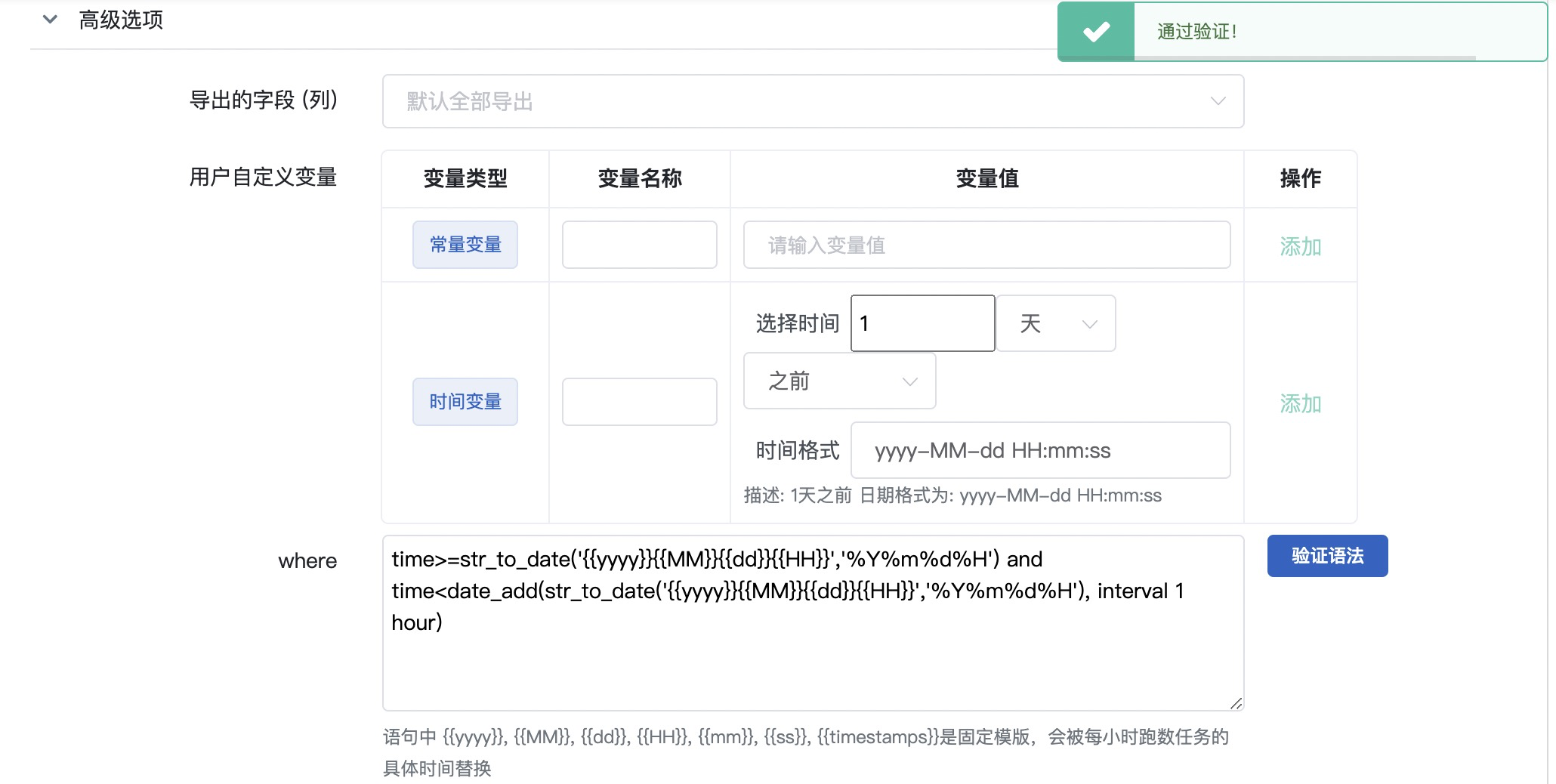
Step4: 填写高级选项
参考截图以及表格信息,填写高级选项
| 条目 | 内容 | 备注 |
|---|---|---|
| 导出字段 | 默认全部导出 | 实际中根据业务选择 |
| 用户自定义变量 | 保持为空 | |
| where | (查看下方SQL语句) | 使用提供的SQL语句进行替换 |
| 数据分区时段 | 0 小时之前 | 修改默认值1为0 |
| 数据分区存储路径格式 | 保持默认 |
SQL语句
time>=str_to_date('{{yyyy}}{{MM}}{{dd}}{{HH}}','%Y%m%d%H') and time<date_add(str_to_date('{{yyyy}}{{MM}}{{dd}}{{HH}}','%Y%m%d%H'), interval 1 hour) |
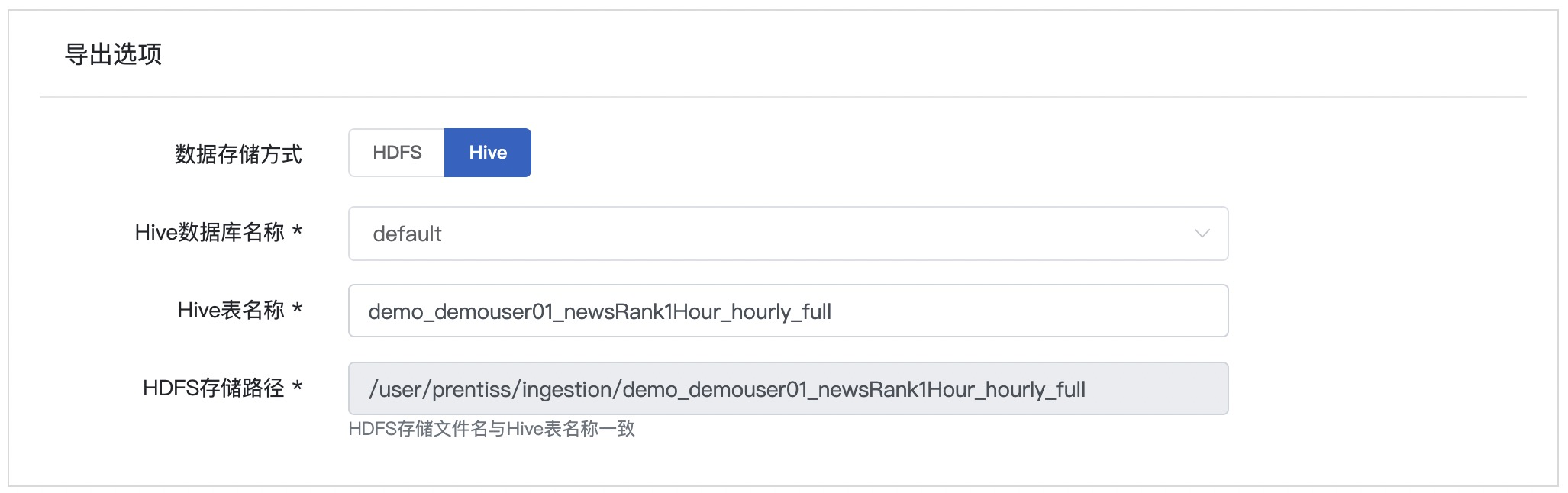
Step5: 填写导出选项
参考截图以及表格信息,填写导出选项
| 条目 | 内容 | 备注 |
|---|---|---|
| 数据存储方式 | Hive | |
| Hive 数据库名称 | spider | 从下拉框选择 |
| Hive 表名称 | demo_demouser01_newsRank1Hour_hourly_inc | 保持不变 |
| HDFS 存储路径 | /user/demouser01/ingestion/demo_demouser01_newsRank1Hour_hourly_inc | 自动生成,保持不变 |
Step6: 保存作业
完成填写之后,划回至页面顶部,点击右上角保存
Step7: 查看作业列表
最后,使用导航「作业管理-作业列表」可以查看创建好的作业

4.3 创建数据清洗作业
目的: 为了对 Hive 表中的数据去重,避免爬取的数据有重复记录,对分析结果造成影响
Step1: 创建Hive作业
通过导航来到「作业管理-新建Hive作业」,参考截图
Step2: 填写基本信息
参考截图以及表格信息,填写基本信息,截图作业名称仅为示例,用户可参考截图进行自定义

| 条目 | 内容 | 备注 |
|---|---|---|
| 名称 | demouser01_spider_hourly_clean_data | demo为安全组名称,可使用实际安全组替换demo,使用用户名_替换demouser01,以免造成重名冲突 |
| 拥有者 | demouser01 | 下拉框选择 |
| 描述 | 对Hive表中的数据去重,避免爬取的数据有重复记录,对分析结果造成影响 | 可替换 |
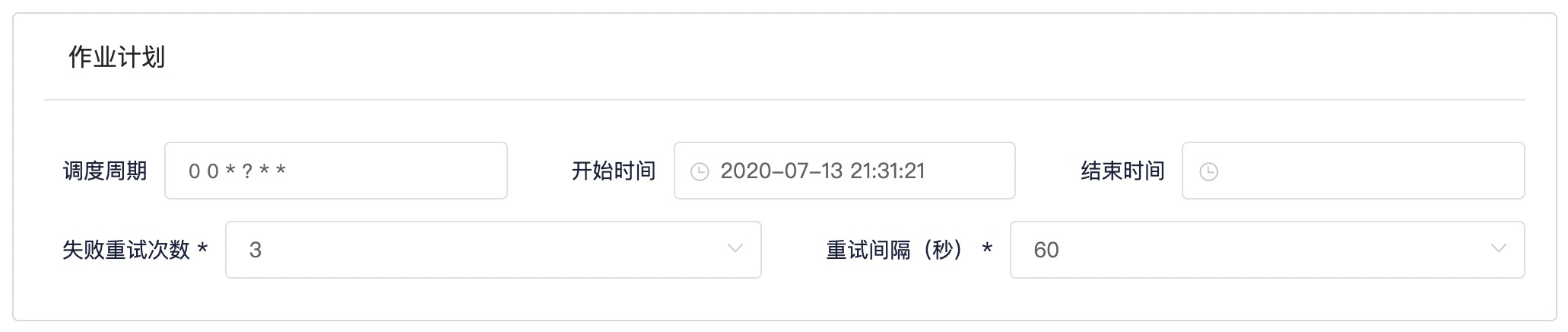
Step3: 填写作业计划
参考截图以及表格信息,填写作业计划
| 条目 | 内容 | 备注 |
|---|---|---|
| 作业调度周期 | 0 0 ? * | Cron表达式,每小时运行一次 |
| 开始时间 | 离当前时间最近的过去整点时间 | 点击输入框改动时间为离当前时间最近的过去整点时间,选择确定 |
| 结束时间 | 置空 | 保持默认 |
| 失败重试次数 | 3 | 保持默认 |
| 重试间隔 | 60 | 保持默认 |
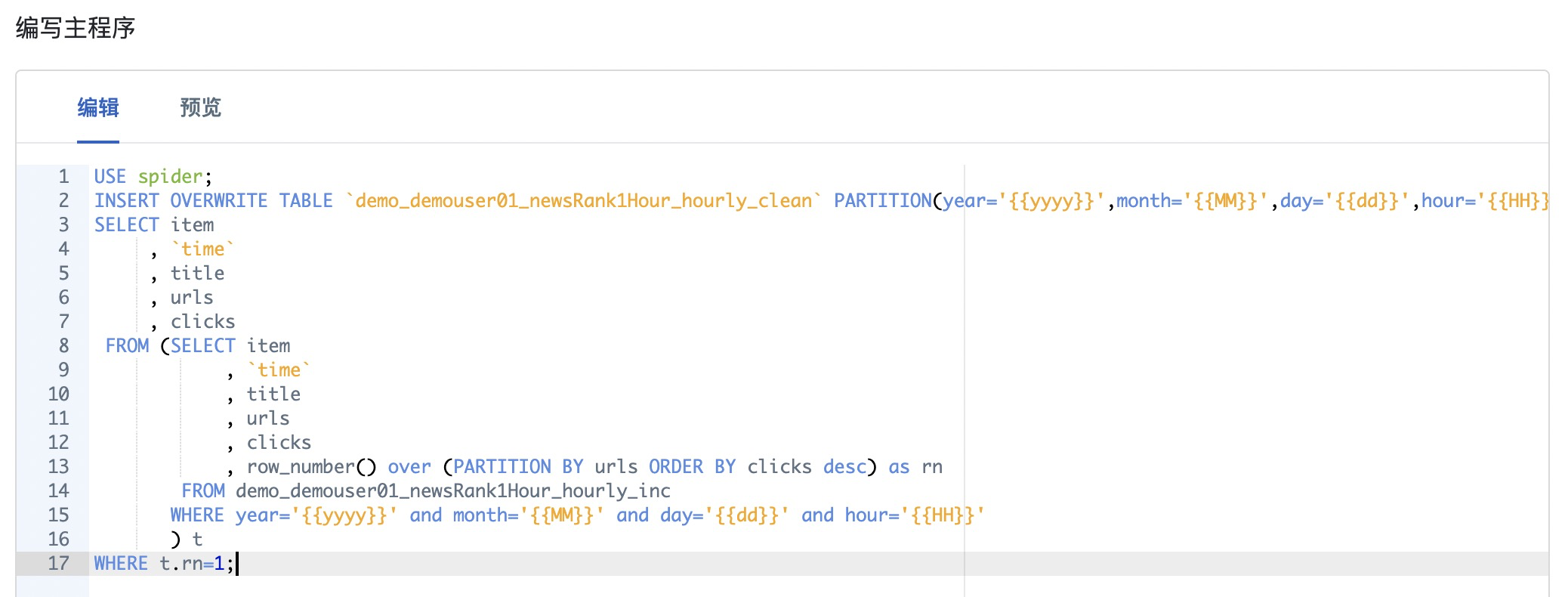
Step5: 填写SQL语句
参考截图以及表格信息,在编写主程序区域填写 SQL
USE spider; |
Step6: 创建作业
完成填写之后,点击右上角创建
Step7: 查看作业列表
最后,使用导航「作业管理-作业列表」可以查看创建好的作业
注: 此时应该看到作业是使用
用户名_替换了demouser01_的作业

4.4 创建数据统计作业
目的: 为了计算出爬取的新闻每小时新增的点击数,并将数据写入到新的 Hive 表中,从而了解到哪些新闻是更受关注的。
Step1: 创建Hive作业
通过导航来到「作业管理-新建Hive作业」,参考截图,创建 Hive 作业
Step2: 填写基本信息
参考截图以及表格信息,填写基本信息
| 条目 | 内容 | 备注 |
|---|---|---|
| 名称 | demouser01_spider_hourly_calculate_data | demo为安全组名称,可使用实际安全组替换demo,使用用户名_替换demouser01,以免造成重名冲突 |
| 拥有者 | demouser01 | 下拉框选择 |
| 描述 | 计算出爬取的新闻每小时新增的点击数, 从而了解到哪些新闻是更受关注的 |

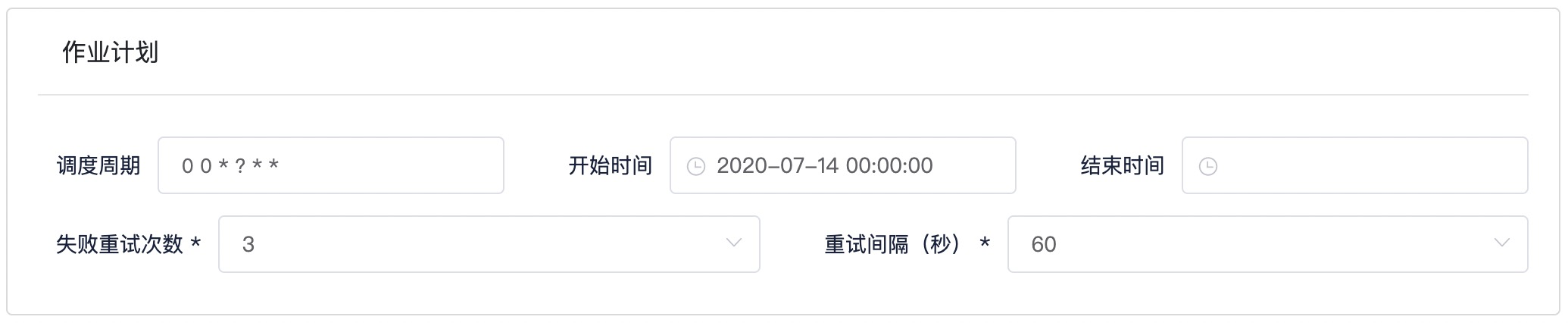
Step3: 填写作业计划
参考截图以及表格信息,填写作业计划
| 条目 | 内容 | 备注 |
|---|---|---|
| 作业调度周期 | 0 0 ? * | Cron表达式,每小时运行一次 |
| 开始时间 | 离当前时间最近的过去整点时间 | 点击输入框改动时间为离当前时间最近的过去整点时间,选择`确定 |
| 结束时间 | 置空 | 保持默认 |
| 失败重试次数 | 3 | 保持默认 |
| 重试间隔 | 60 | 保持默认 |
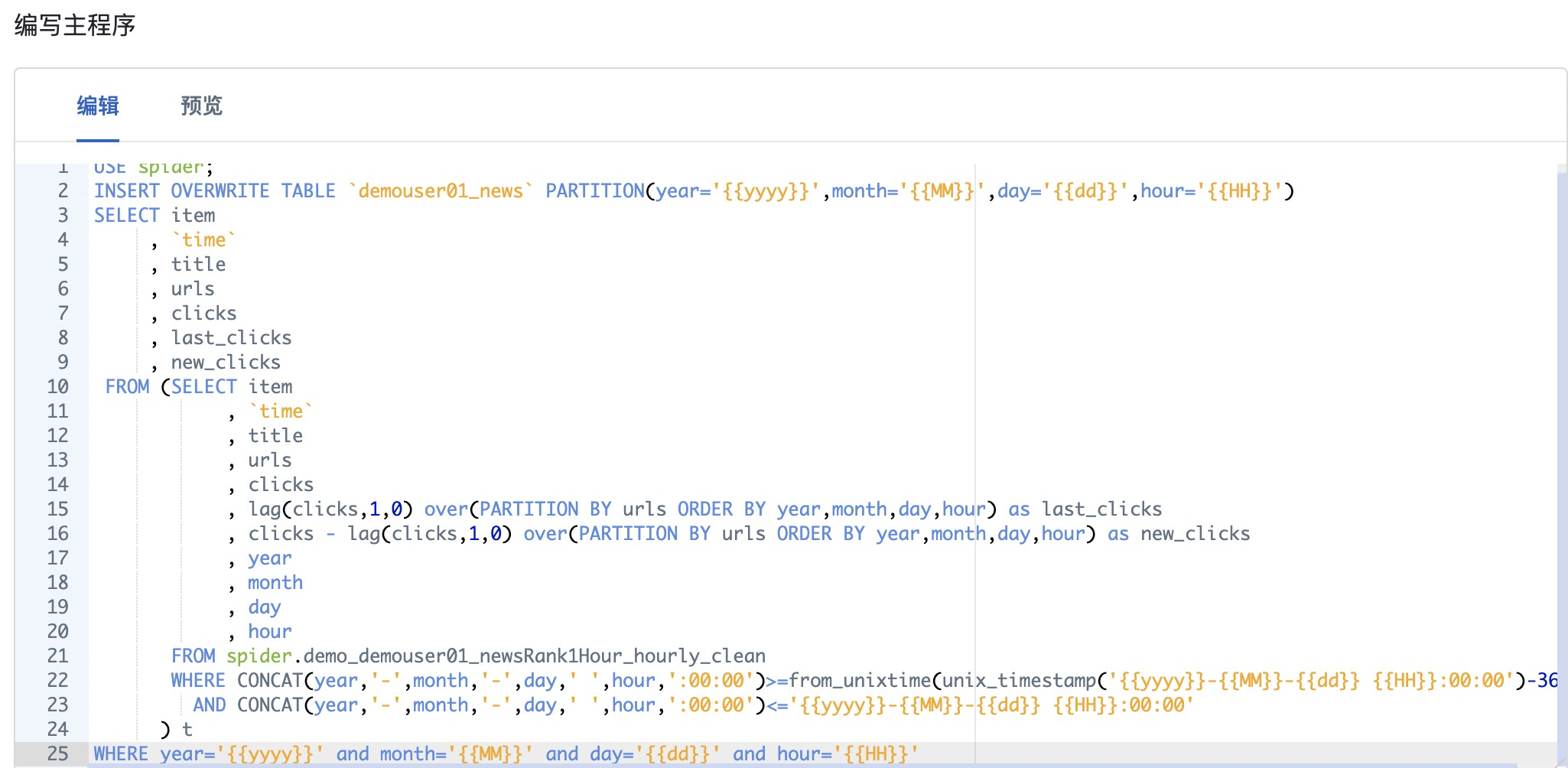
Step4: 填写SQL语句
参考截图以及表格信息,在编写主程序区域填写 SQL
USE spider; |
注: 此时应该看到作业是使用
用户名_替换了demouser01_的作业
最后,使用导航「作业管理-作业列表」可以在列表里面看见创建好的作业
Step5: 创建作业
完成填写之后,点击右上角创建
Step6: 查看作业列表
最后,使用导航「作业管理-作业列表」可以在列表里面看见创建好的作业
注: 此时应该看到作业是使用
用户名_替换了demouser01_的作业

4.5 创建数据转换作业
目的: 将计算后的数据转换并且输出到MySQL主题数据库,用于后面的数据可视化操作
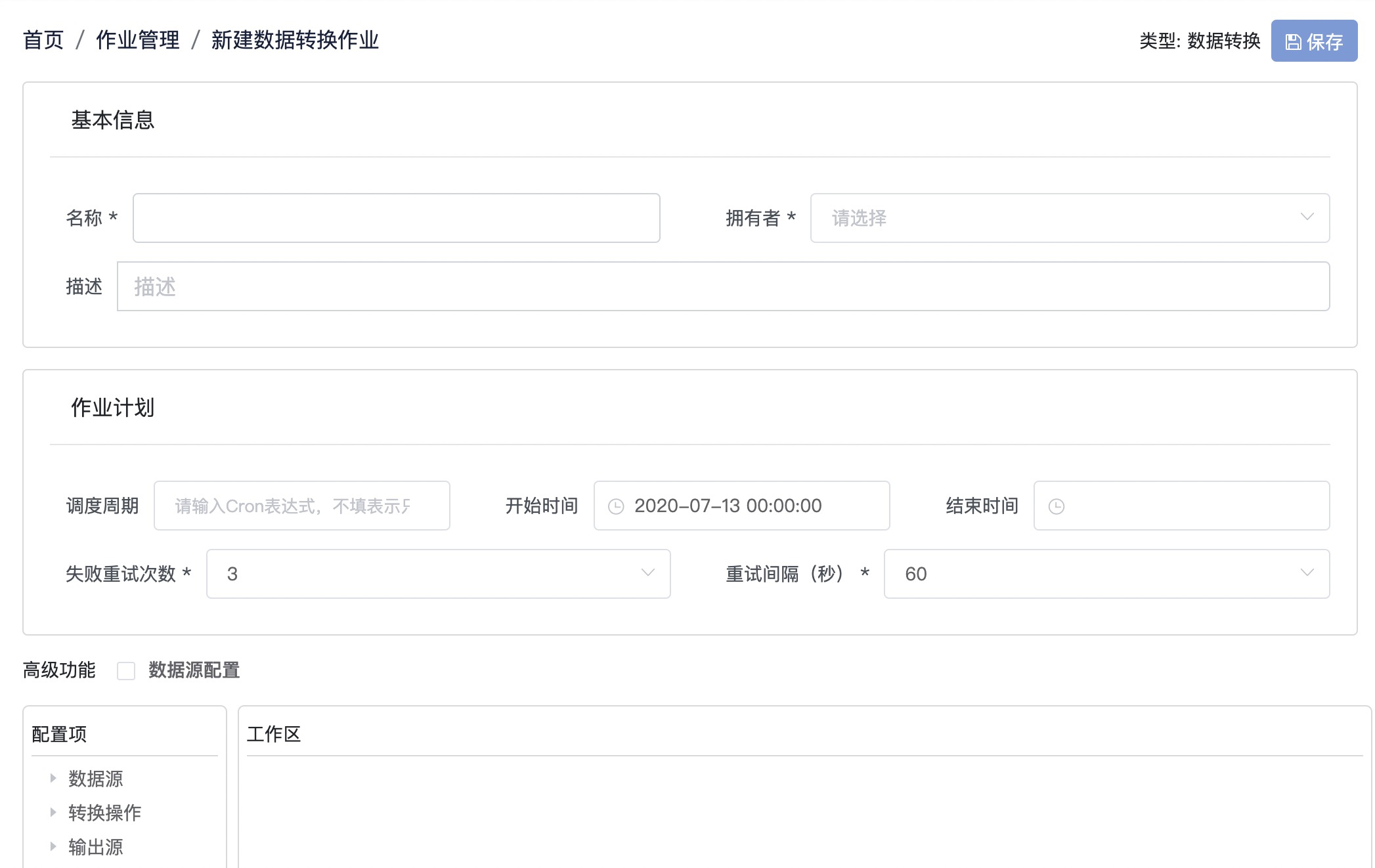
Step1: 创建数据转换作业
通过导航来到「作业管理-新建数据转换作业」,参考截图,创建数据转换作业
Step2: 填写基本信息
参考截图以及表格信息,填写基本信息,截图作业名称仅为示例,用户可参考示例进行自定义命名
| 条目 | 内容 | 备注 |
|---|---|---|
| 名称 | demouser01_spider_hourly_export | demo为安全组名称,可使用实际安全组替换demo,使用用户名_替换demouser01,以免造成重名冲突 |
| 拥有者 | demouser01 | 下拉框选择 |
| 描述 | 将计算后的数据转换并且输出到MySQL数据库 | 描述信息可替换 |
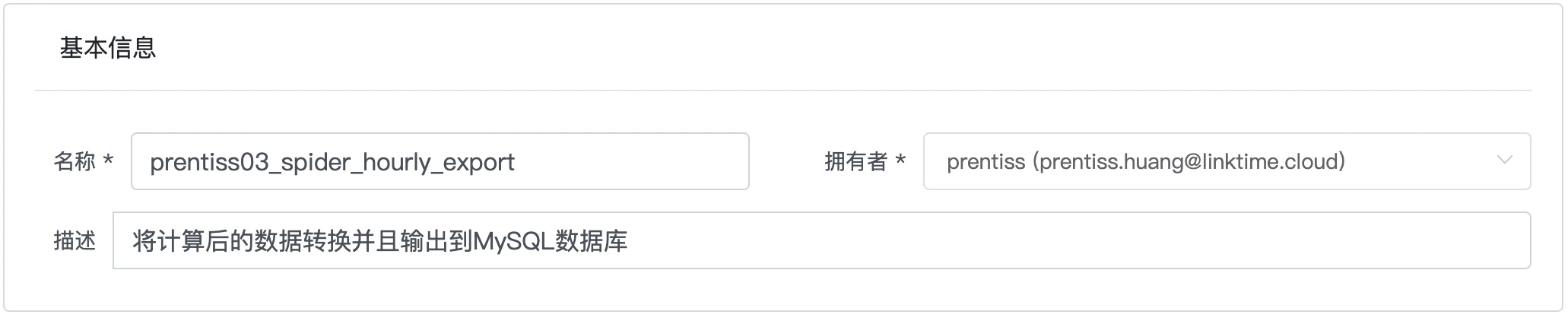
Step3: 填写作业计划
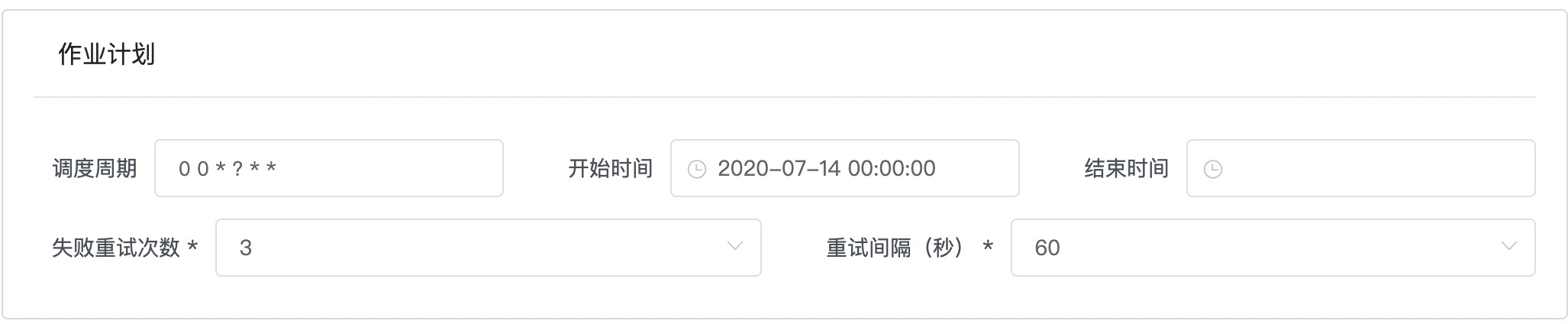
参考截图以及表格信息,填写作业计划
| 条目 | 内容 | 备注 |
|---|---|---|
| 调度周期 | 00*?** | 下拉框选择,cron表达式,语义是每小时运行一次 |
| 开始时间 | 保持默认 | 保持默认 |
| 结束时间 | 置空 | 保持默认 |
| 失败重试次数 | 3 | 保持默认 |
| 重试间隔 | 60 | 保持默认 |
Step4: 选择数据源
参考截图,选择工作区Hive数据源
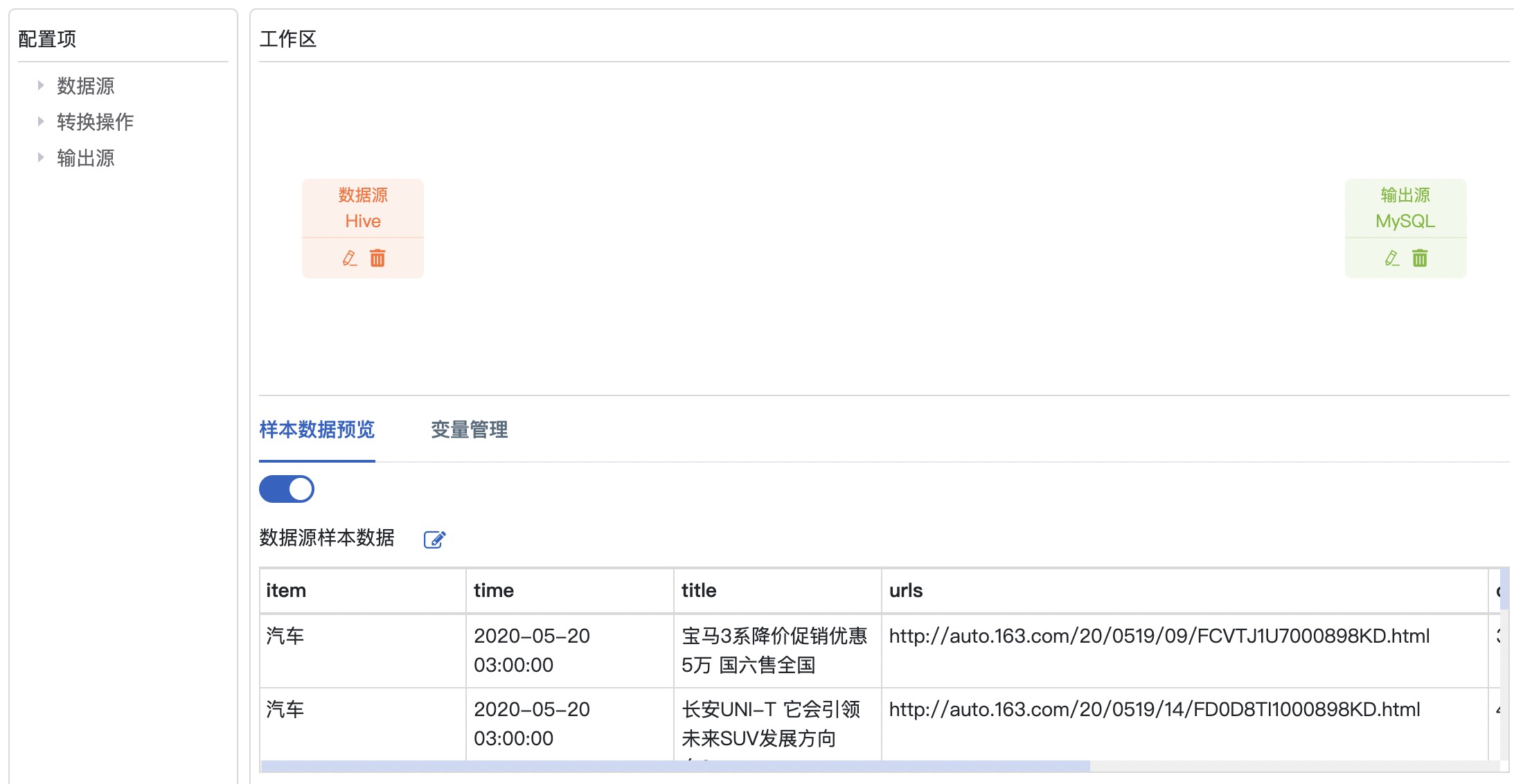
Step5: 配置数据源
点击编辑图标,进入配置数据源页面,选择MySQL数据源,参考截图以及表格信息,点击保存
| 条目 | 内容 | 备注 |
|---|---|---|
| 数据源 | spider | 点击下拉选择 |
| 表 | demouser01_news | 下拉框选择 |
| Query | – | 自动生成的默认语句 |
| Fields | – | 自动生成的全量字段 |
Step6: 配置输出源
点击编辑图标,参考截图以及表格信息,配置输出源
| 条目 | 内容 | 备注 |
|---|---|---|
| 数据源 | spider_demo | 下拉框选择 |
| 表 | demouser01_newsAdd2 | 下拉框选择 |
| 数据变更 | Replace | 下拉框选择 |
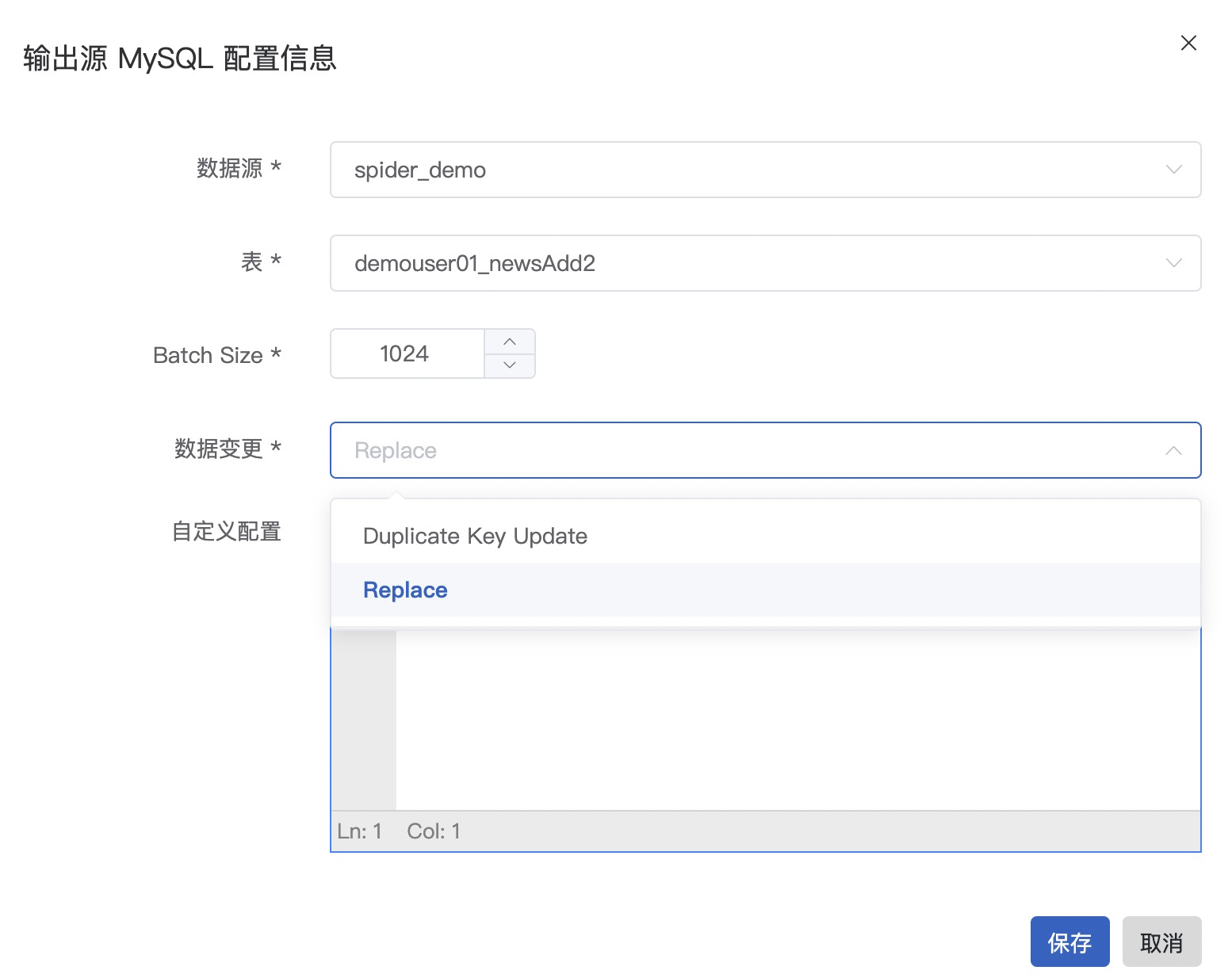
划回至页面顶部,选择保存并在弹出框选择确定
Step7: 查看作业列表
4.6 创建端到端的工作流
目的: 前面小结创建的都是单个的作业,现在使用一条工作流将他们串联起来,并且配置依赖关系,配合调度系统,做到自动化整个过程
Step1: 创建新工作流
参考截图,使用导航「工作流管理-新建流水线」创建一个新的工作流
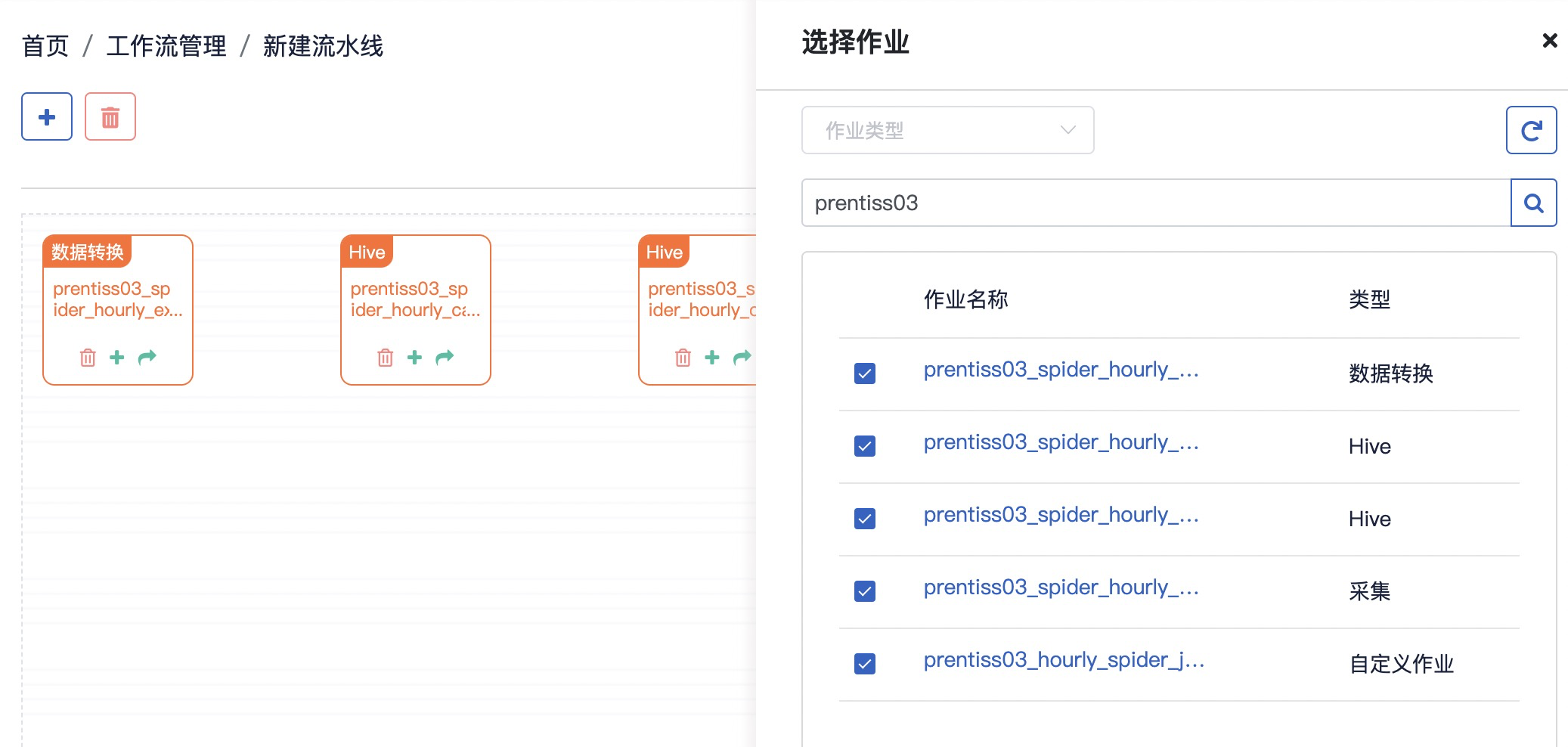
Step2: 筛选作业
参考截图,在工作流画布,点击图标+,作业类型选择采集、Hive、数据转换和自定义作业,搜索demouser01,快速找到对应作业,点击勾选框添加
注: 这里应该找的是
用户名_替换demouser01的作业
Step3: 调整作业顺序
参考截图,根据业务流程,使用鼠标拖拽调整作业的先后顺序:「爬取数据(spider)->采集数据(collect)->清洗数据(clean)->计算数据(calculate)->整理输出表(export)」
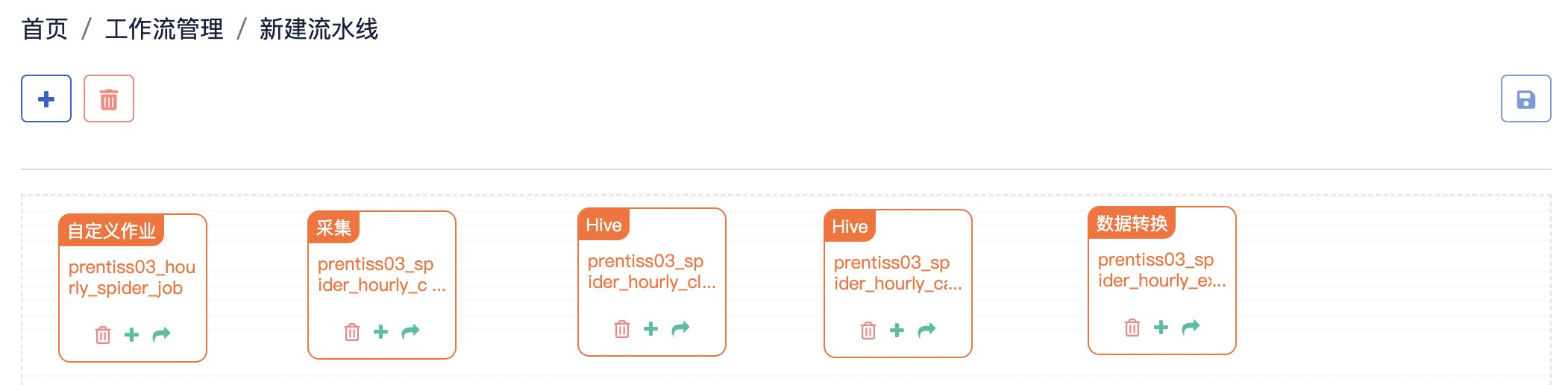
Step4: 关联作业
参考截图,拖拽小方块的绿色加号按钮,可以拉出一个连接线用来关联两个作业
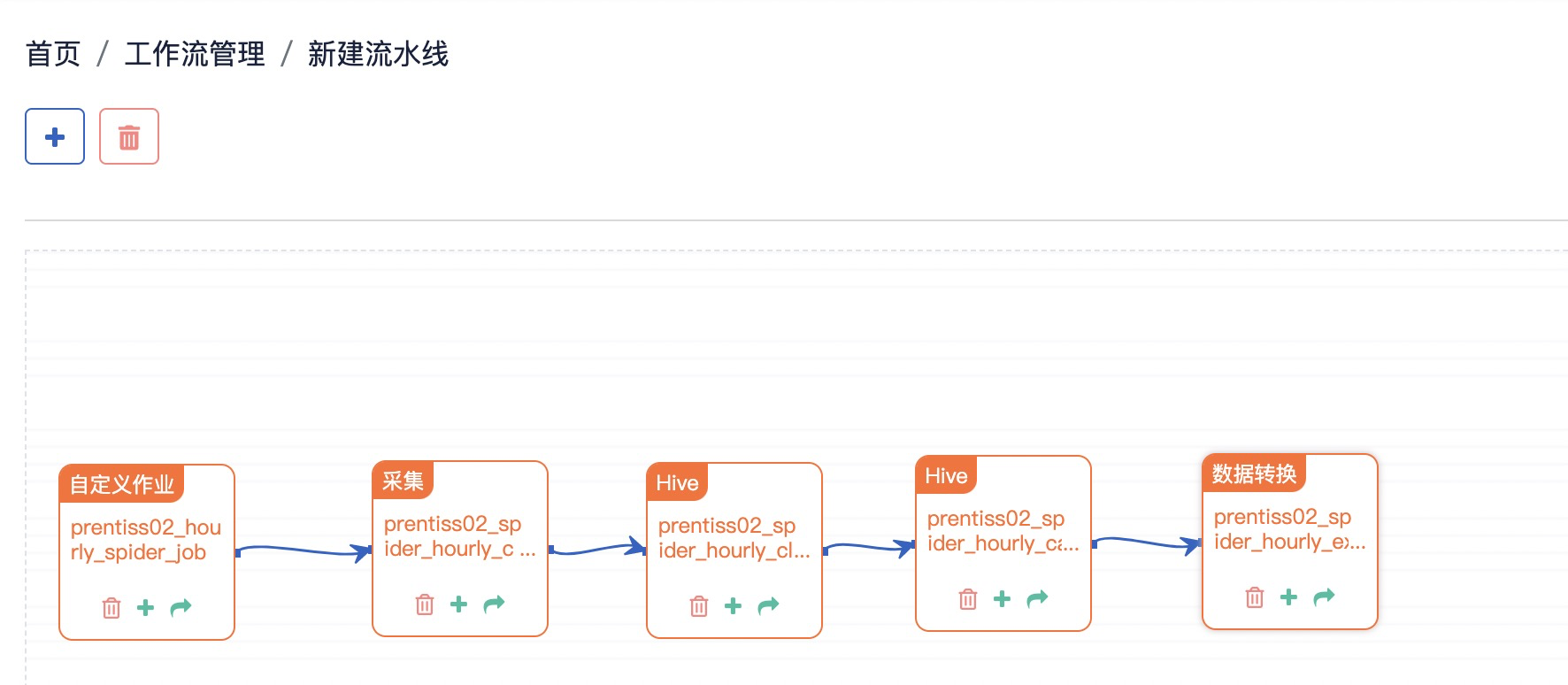
Step5: 保存工作流
点击保存按钮,命名工作流为demouser01_e2e_hourly_pipeline_workflow, 用户使用 用户名_替换demouser01_
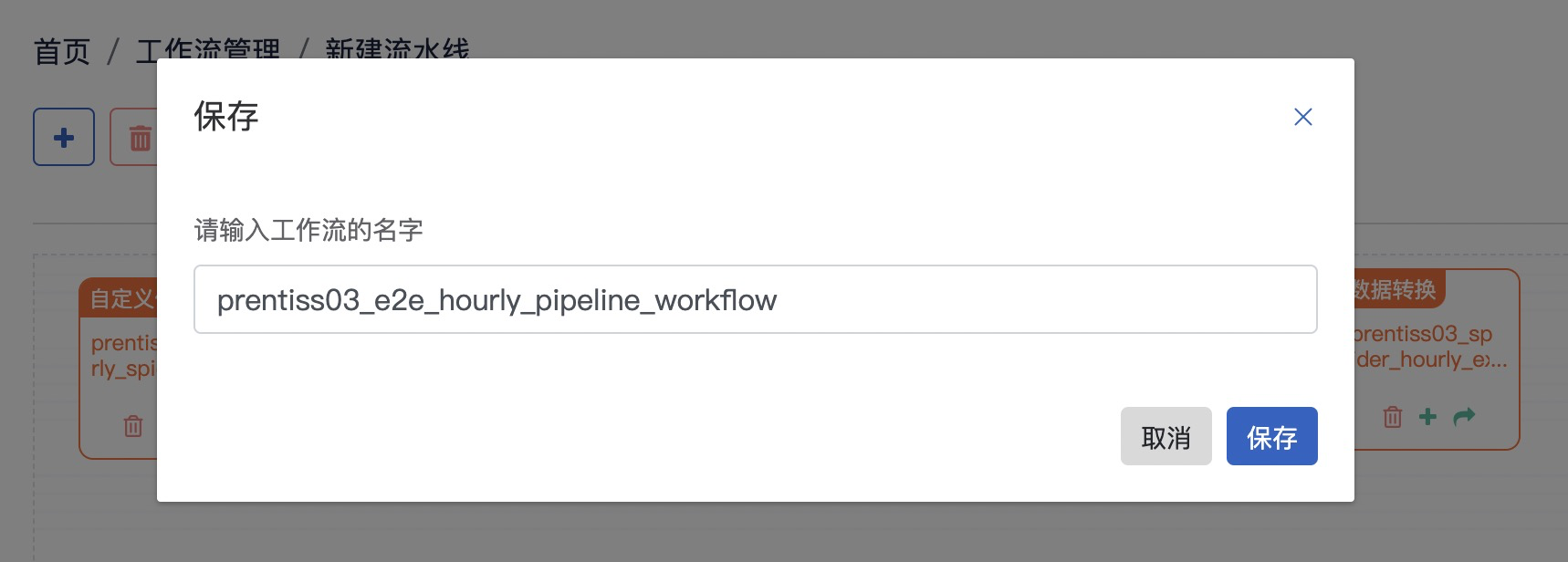
Step6: 启动工作流
参考截图,查看已经建立好的工作流,点击操作栏位的启动按钮后在弹出框点击前往确定

Step7: 查看工作流状态
参考截图,导航「作业管理-作业列表」,查看作业状态
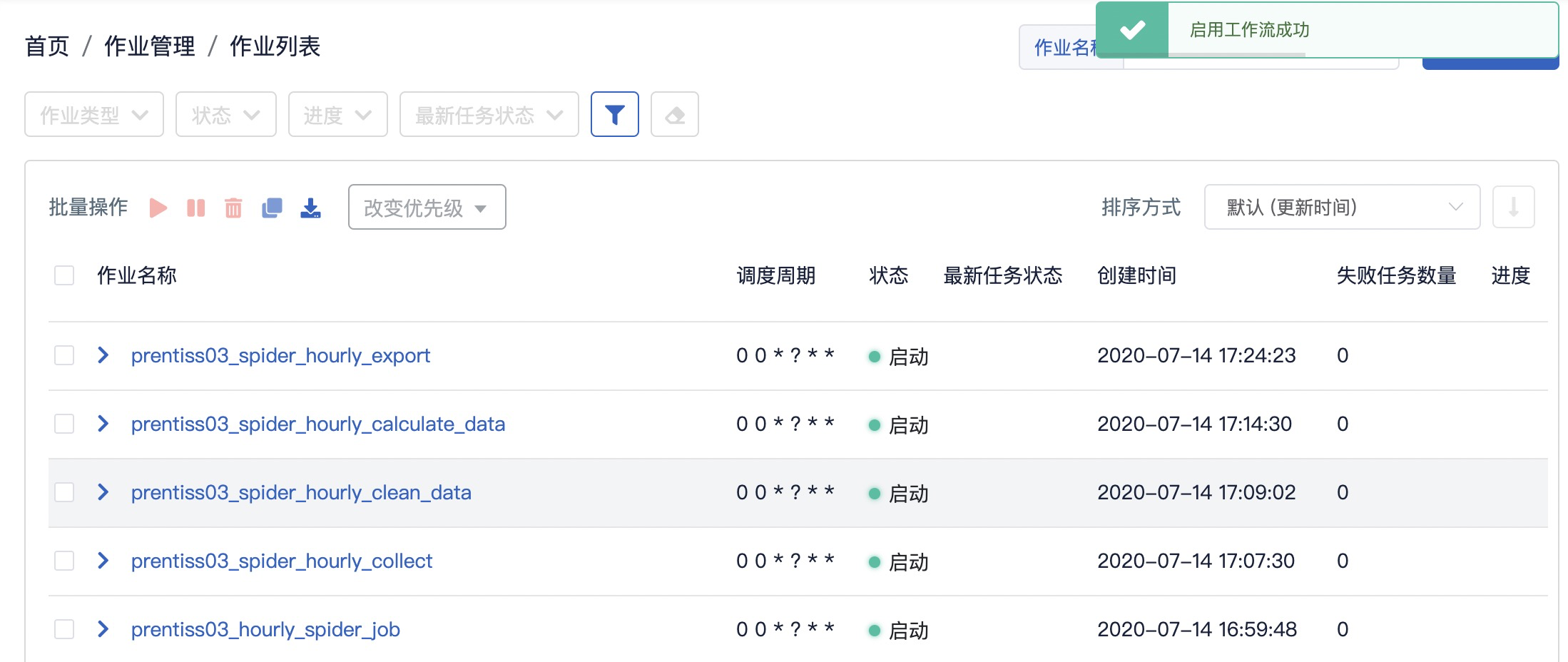
注:作业进度会有延迟状况,但不影响作业运行
Step8: 验证工作流状态
参加截图,导航「作业管理-作业列表」查看任务运行状态

经过一段时间的运行,工作流上面的作业通过相互依赖已经顺利运行完毕,并且正常输出,点击每个任务,可以看到输出详情,此时可以进入数据可视化的阶段
4.7 添加Hive数据保留策略
为指定的Hive库表添加Hive数据保留策略,定期清理数据
Step1:用户在【数据资源-Hive数据保留策略】点击进入
点击右上角的添加策略
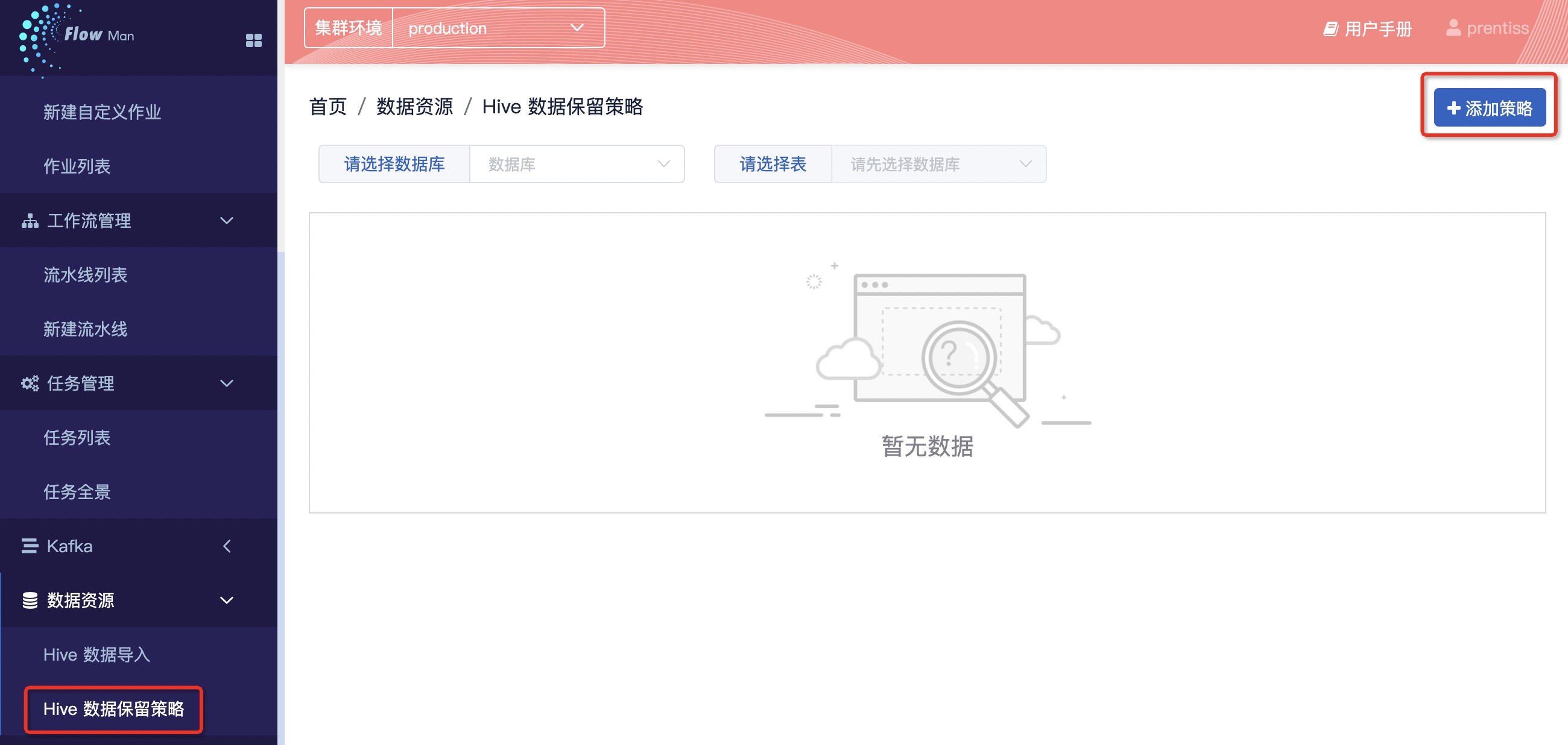
Step2:添加策略
参考表和截图进行填写
| 名称 | 内容 | 补充 |
|---|---|---|
| 数据库* | spider | |
| 数据表* | demouser01_news | 本教程使用的Hive结果表 |
| 包括数据时长* | 72 | 用户可自定义 |
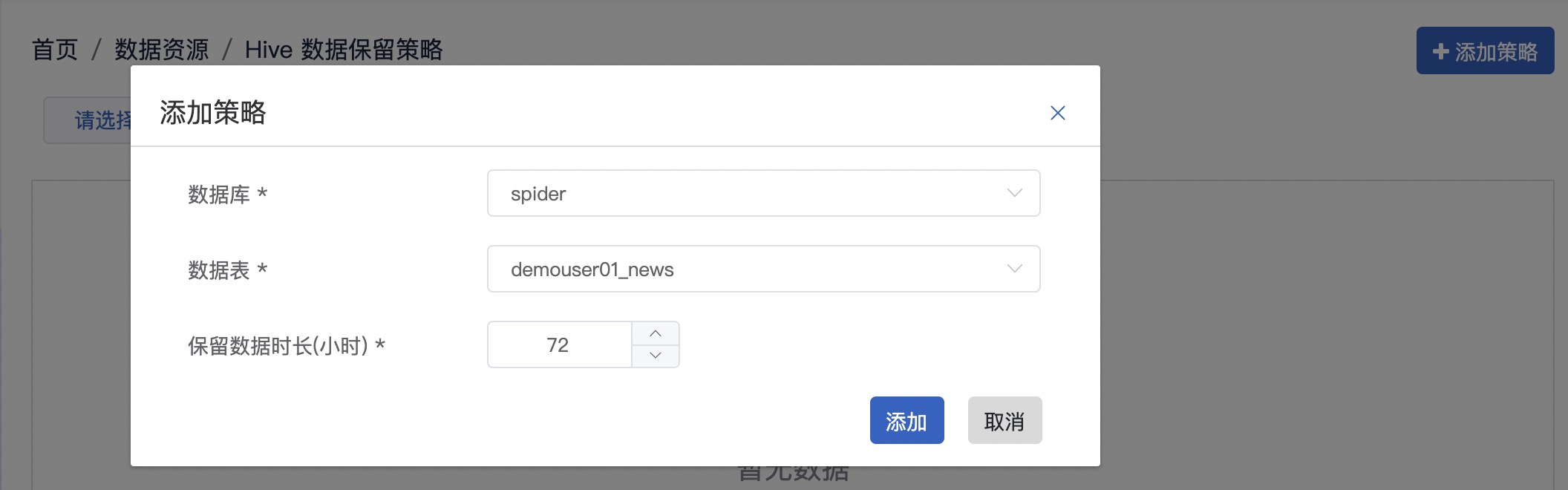
填写完成后,可在【Hive】数据保留策略界面进行查看、编辑
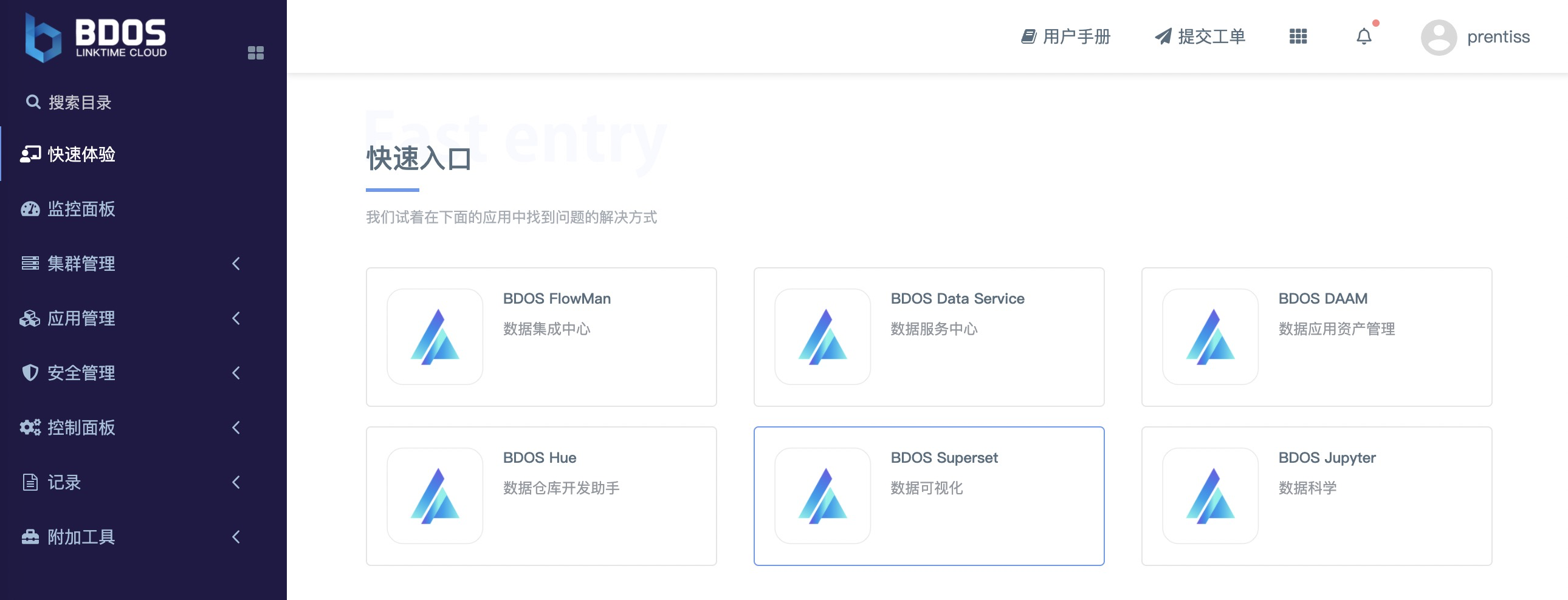
4.8 使用 Superset 查看数据可视化
4.8.1 Superset添加数据库
运行完FlowMan上面步骤创建的作业后, 通过BDOS界面导航「快速体验-快速入口」点击BDOS Superset进入。
Step1-添加数据库
点击导航「数据源-数据库」后,点击+添加数据库
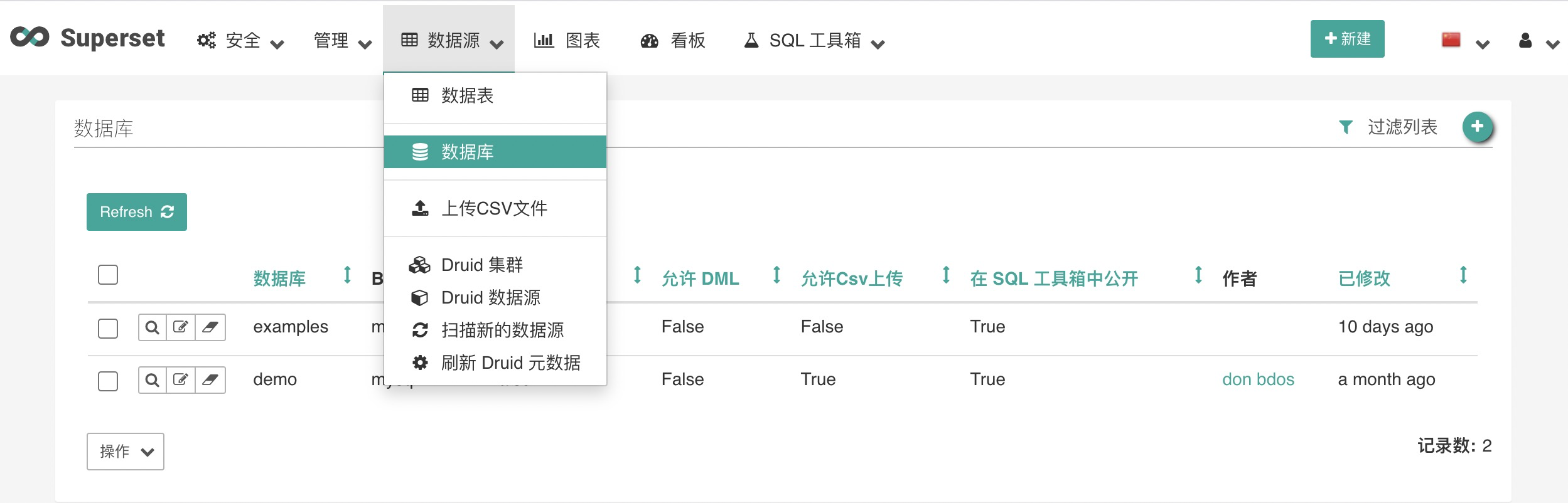
| 数据库 | 内容 |
|---|---|
| 数据库 | demo |
| SQLAlchemy URI | mysql://root:123456@admin-linktime-mysql.marathon.l4lb.thisdcos.directory:3306/demo?charset=utf8 |
其他的选项保持默认,点击保存,查看添加的数据库
Step2-添加数据表
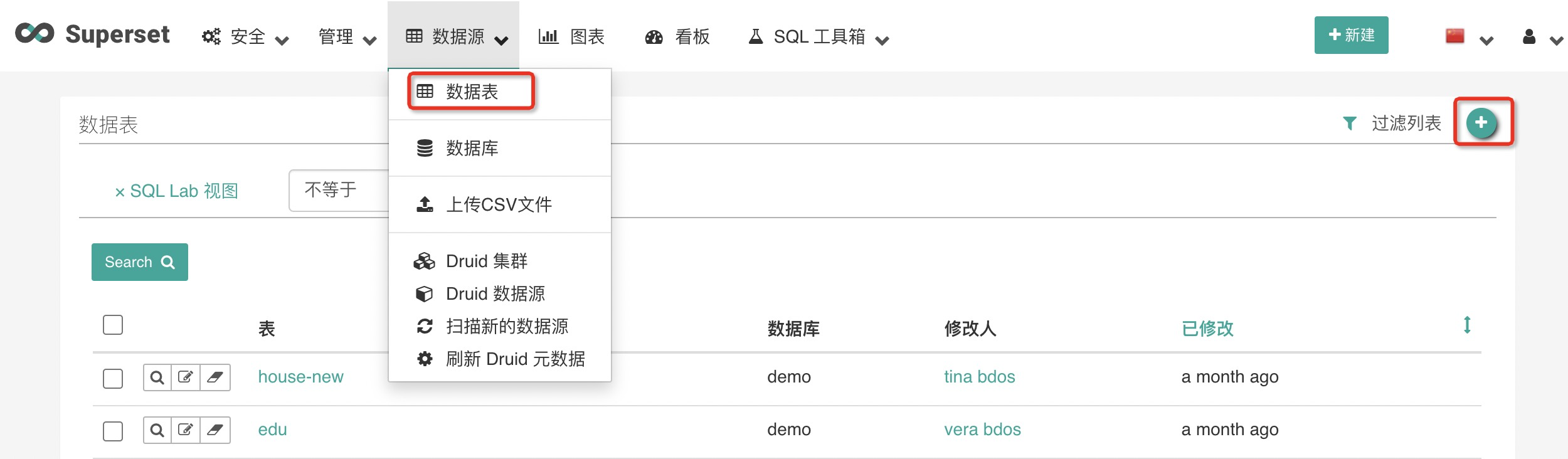
点击导航「数据源-数据表」后,点击+添加数据表
参考截图和表格填写内容
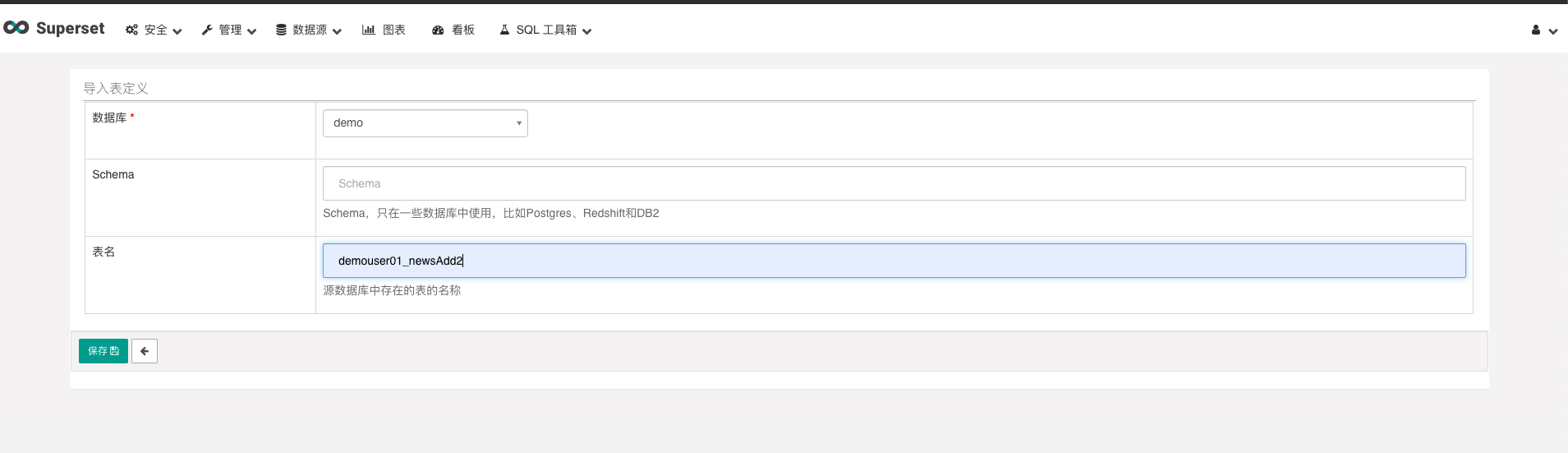
| 内容 | 内容 |
|---|---|
| 数据库 | demo |
| SQLAlchemy URI | (保持为空) |
| 表名 | demouser01_newsAdd2 |
Step3: 打开图表
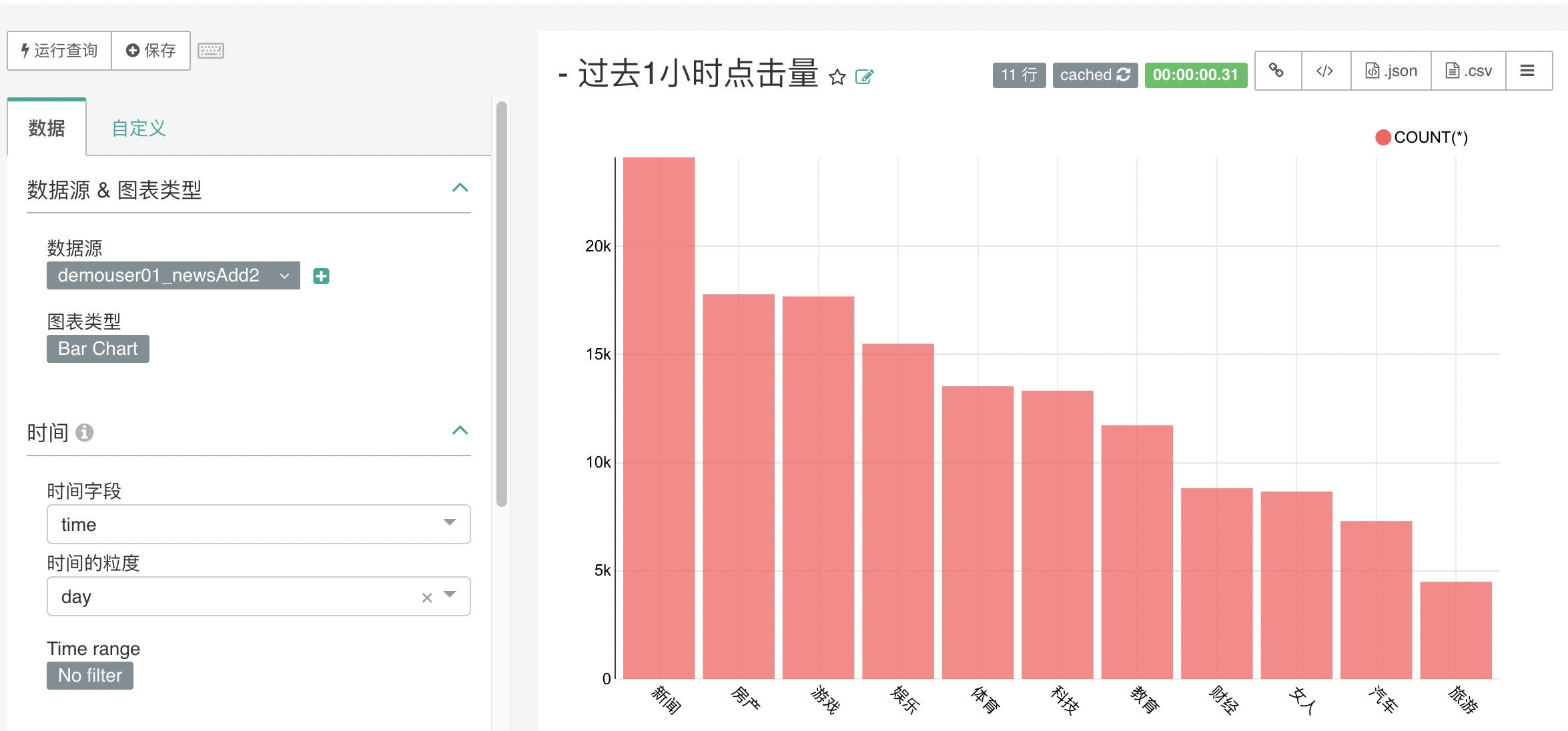
参考截图,通过导航至「图表」,创建基于输出表作为数据源的图表,点击新建的图标

Step4: 选择数据源
参考截图,选择数据源,和想要创建的图表类型
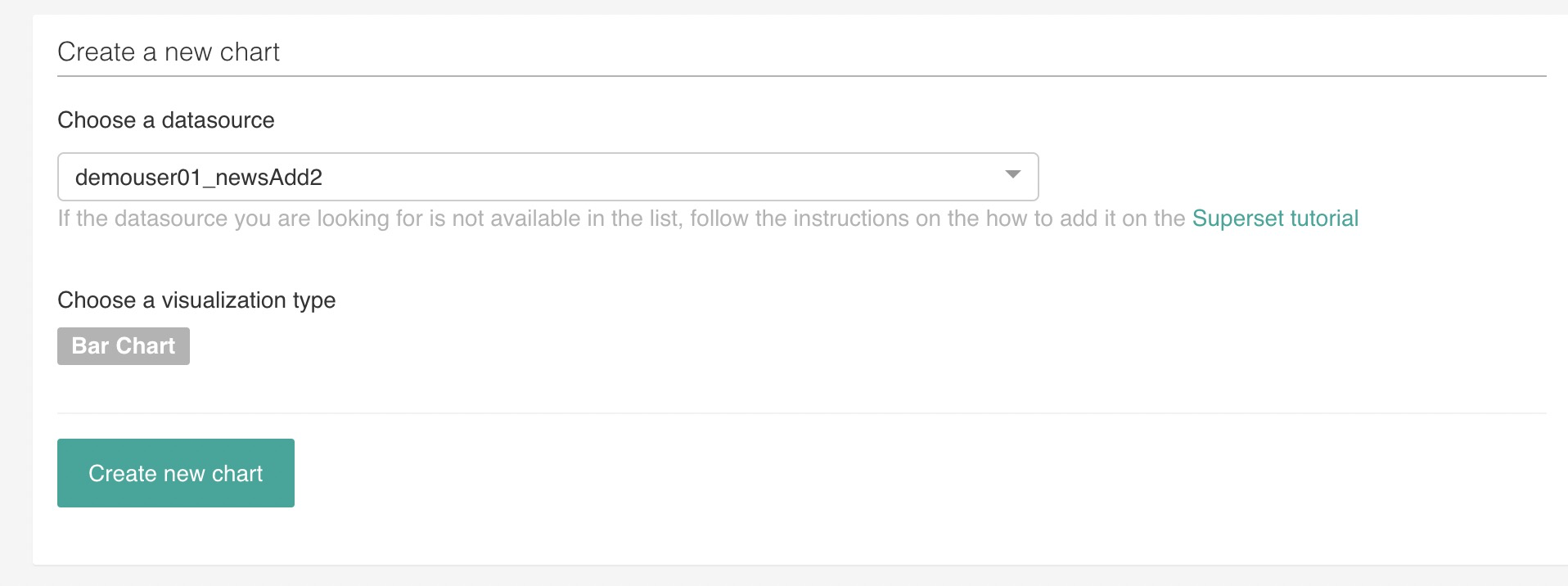
Step5: 设置数据源
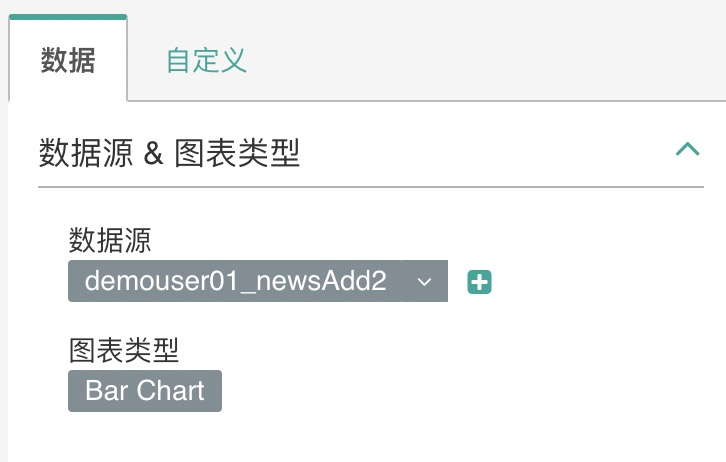
参考截图,设置数据源&图表类型 这里保持不变
Step6: 设置时间
参考截图,设置时间 将时间范围修改成为 No filter

Step7: 设置指标
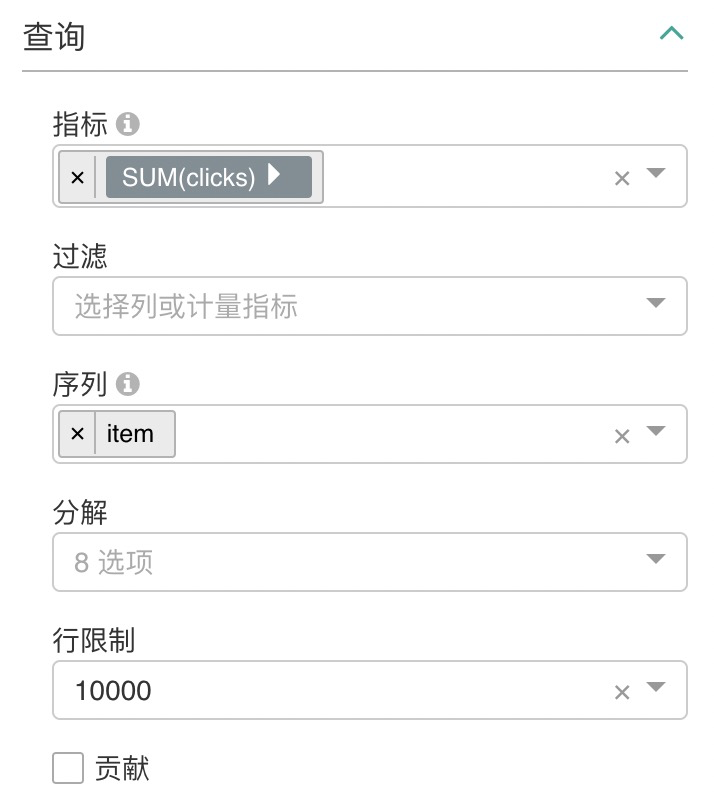
参考截图,查询参数
设置查询指标为 sum(clicks) 设置序列为 item
Step8: 运行并保存 Chart
运行查询,并未生成的 Chart 起一个名字,随后点击Save退出
这里推荐加上
用户名_作为前缀